The rapid growth of Microsoft® Teams within enterprises has led to unparalleled growth in content, with numerous Teams sites creating data duplication, document redundancy, and version control issues. As a result, content sprawl has become quite real quite quickly, creating governance challenges, user frustration, and productivity dips with content located across channels, chats, and emails. But it’s not all doom and gloom.
There is a way to tackle content sprawl and chaos, creating a productive environment to power modern work. By integrating content services with the applications employees use to produce and consume content, such as Microsoft® 365, organizations give users direct access to accurate content, prevent ungoverned content sharing, and put an end to the digital friction holding back efficient operations. Let’s explore how.
Understanding content sprawl and related challenges
Put productivity tools, such as Microsoft 365, into the hands of employees and you’d expect improved productivity, control, and connection. But that is not always the case.
Content sprawl has created significant content management challenges, with high volumes of disorganized content spread across expected and unexpected locations, making it difficult for users to find.
A recent Foundry survey sponsored by OpenText™ found that employees spend up to three hours a day searching for information to do their jobs. Adding insult to injury, 58% of organizations have lost business opportunities due to an inability to access data in a timely manner.[1]
While Microsoft 365 users enjoy easy document creation, collaboration, and communication, three challenges often hold productivity back:
Content sprawl: Employees’ options for sharing capabilities, such as OneDrive and Teams, lead to duplicate documents and process improvisation.
Process disconnect: Processes are disconnected from content and data leading to content siloes across applications.
Complexity and loss of control: Disconnected content spread across systems, applications, and even desktops, creates governance control issues, increasing data security risk.
Combatting content sprawl with modern cloud content management
With organizations facing varying degrees of content sprawl, along with varying stages of cloud transformation, it’s not always realistic for enterprises to move all content to the cloud at once. For many, a hybrid approach to corralling content and reducing sprawl is the best path forward, in which some information and systems are kept on-premise and some moved to the cloud, whether private, public, or hyperscalers such as Google, AWS, or Microsoft® Azure.
A hybrid architecture allows organizations to take a phased approach to moving content and processes to the cloud. With cloud-based content services, organizations get the flexibility to adapt to any infrastructure, moving at a pace that makes sense for the business.
Cloud-based content services provide a way to boost integrity, availability and accountability to all locations where content lives. By leveraging automation and integration across the information lifecycle, policies can be enforced across all content repositories and platforms. Plus, organizations can create flexible digital workspaces that enhance information access and value—giving users an alternative to creating ad-hoc Teams and other content locations.
This is done by integrating content within the lead applications employees use every day, including Microsoft 365, leaning on intelligent automation to ensure information is tied to specific tasks and workflows. For example, connecting SharePoint to ERP or CRM systems to organize content alongside business processes allows businesses to centralize content, people, workflows and tasks in one place.
Improving information governance to control content sprawl
With information constantly on the move and created wherever work is being done, such as within Microsoft Teams, the sprawl and chaos leads to unknown, uncontrolled, unsecured and unaudited content. With ungoverned content comes organizational risk—employees are uncertain they are working with the most recent and relevant content.
Therefore, information governance needs to evolve to support modern work environments, allowing organizations to take advantage of new collaboration tools while governing the ever-expanding amount of content and data.
According to Deloitte, effective information governance delivers a meaningful return on investments, in multiple forms:[2]
Generating incremental revenue through more efficient, profitable use of information
Reducing ‘hard’ costs by streamlining technology and storage needs
Saving time by enabling employees to find and use information more easily and quickly
From chaos to connected work experiences
By extending enterprise-grade content management deeper within the organization, and integrating content within already familiar interfaces, such as Microsoft Teams, employees get needed access and insights within the applications they use every day. With cloud-based content management equipped with governance controls, organizations can shift from content chaos to content connection, gaining tools to collaborate and share information across business systems and locations to help the workforce work better together.
As a result, productivity benefits are ripe for the taking, keeping users grounded in a consistent business workspace to break down information siloes, create empowered teams and reduce additional sprawl.
Ready to reduce content sprawl and deliver connected work experiences? Learn how to master modern work with smarter information.
[1] Foundry Research sponsored by OpenText™, MarketPulse Survey: Digital Friction, September 2023
[2] Deloitte, “The information governance imperative,” 2022
Application delivery management (ADM) plays a pivotal role in ensuring the seamless deployment, monitoring, and optimization of software applications. We’re well into 2024, and we can see the ADM field is poised for significant transformations, fueled by emerging technologies, evolving market demands, and heightened consumer expectations. Let’s dive into what we can anticipate in the realm of application delivery management this year and explore three essential trends your competitors are using to get a leg up.
Accelerate application delivery without compromising quality.
They are using or setting the stage for AI and Machine Learning in ADM.
Artificial Intelligence (AI) and Machine Learning (ML) are set to revolutionize application delivery management in 2024. Harnessing the power of AI-driven analytics, ADM platforms can proactively anticipate and mitigate potential performance issues, optimize resource allocation, and automate mundane tasks with unprecedented efficiency. ML algorithms, capable of analyzing vast troves of data generated throughout the application lifecycle, offer actionable insights for continuous improvement.
Expect to witness a surge in the adoption of AI-driven ADM solutions, empowering organizations to elevate application performance, reliability, and user experience to new heights. By leveraging AI and ML technologies, your ADM team can not only enhance operational efficiency but also unlock new avenues for innovation, driving competitive advantage—which could mean the difference between being in business and not.
They are shifting toward cloud-native technologies.
The momentum behind cloud-native technologies continues to gain traction, reshaping the ADM landscape in 2024. With your competitors increasingly embracing cloud platforms, ADM strategies are evolving to embrace the unique challenges and opportunities of cloud-native environments. Technologies like Kubernetes, containerization, and microservices architectures are emerging as foundational pillars of modern application delivery, offering unparalleled scalability, agility, and resilience.
Your ADM team might want to prioritize upskilling in cloud-native technologies and methodologies to effectively navigate the complexities of modern application environments. By embracing cloud-native principles, you can unlock the full potential of cloud computing, enabling rapid innovation, seamless scalability, and enhanced resilience in the face of evolving business requirements.
They are focused on security and compliance.
In an era marked by escalating cyber threats and stringent regulatory requirements, security and compliance take center stage in ADM practices in 2024. With applications increasingly becoming prime targets for cyber attacks, ensuring robust security measures throughout the application lifecycle is paramount. And your competition knows it. From implementing secure coding practices to conducting continuous vulnerability assessments and compliance audits, they are integrating security into every facet of application delivery management.
In addition, adherence to data privacy regulations such as the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA) is imperative for maintaining customer trust and avoiding regulatory penalties. Expect to see a heightened focus on DevSecOps practices and tools designed to embed security into the DNA of application development and delivery processes seamlessly. By embracing a proactive approach to security and compliance, your team can mitigate risks effectively, safeguard sensitive data, and uphold the integrity of your applications amid all the threat.
Keep an eye on the trends in ADM
This year promises to be full of transformation for ADM, characterized by the rise of AI and machine learning, the proliferation of cloud-native technologies, and a renewed focus on security and compliance, and your competitors are keeping up. By embracing these trends and adopting best practices, your team can navigate the evolving ADM landscape successfully and deliver exceptional digital experiences that drive business growth and customer satisfaction.
Learn more and find resources—including the Forrester® Research, Inc. predictions for application delivery in 2024—to help you master application delivery.
AI is bringing us into a new epoch of human society—it is a force multiplier for human potential.
OpenText is about Information Management + Data + AI + Trust.
AI also reflects its creators. We are currently at a critical point with AI. This is our moment to build the future that we want to live in.
AI can carry implicit bias and perpetuate unequitable power structures. We are on a journey to hear from a wide variety of voices and learn new perspectives on how to build AI that is sustainable, ethical, and inclusive.
As part of our celebrations for Black History Month, I recently had an incredible conversation with Karen Palmer, Storyteller from the Future, Award-winning XR Artist, and TED Speaker who explores the implications of AI and technology on societal structures and inequality. Karen won the XR Experience Competition at South by Southwest (SXSW) 2023 with her most recent project, Consensus Gentium, designed to drive discussion about data privacy, unconscious biases, and the power of technology.
I am thankful to Karen for sharing her powerful and insightful ideas with OpenText, and exploring with us the idea of decolonizing AI. You can read highlights from our conversation below.
***
Mark: As humans, why do you think we need AI?
Karen: The most important aspect or characteristic of AI is efficiency and speed. So, not about accuracy off the bat. It’s going to make things more efficient for you and it’s going to make it quicker for you. That’s a service they’re providing for you.
It’s all being driven around commerce, capitalism, and then the other side of it is surveillance. Like when Charles was crowned king, that was when they kicked in the most complicated and far-reaching AI system, facial recognition system, that’s ever been in England.
You and I may think, “hey, do I need AI?” But we haven’t got a choice in what’s happening today, because it’s being suggested to us.
My view on smart cities is that I really call them “surveillance cities,” because everything is sold to us as “it’s going to be more efficient, speedy, and make our life more safe.” But what it does is that it brings in more measures of security.
So, for example, Robert Williams in Detroit was the first person arrested by the facial recognition system that got it wrong. That was a system called Project Greenlight, and it was presented to the city of Detroit and recommended because there was so much crime. That if they put this surveillance grid in there, it would be better for fighting crime, to keep them safer. And what happened is that it’s now surveilling people and arresting people of color and they can’t dismantle that system. It’s here now.
So we have to be very aware of what is being sold to us and how we would like to use it. And by “us,” I mean all people. It might impact people of color or black people or women or minorities first, but it’s going to impact all of us eventually.
Mark: Thank you for sharing that. We’re here to challenge ourselves today. You used this expression, “chains of colonial algorithms,” and you also used a term, “decolonizing AI.” I’d love to hear your voice on what does that mean to you and what should we take away from that?
Karen: I’ve been looking at bias in AI since 2016-2017. But the deeper I go into it, the more I feel that maybe that term is a little bit of an understatement. That we really need to look at decolonizing AI and dismantling the colonial biases which are deeply embedded within these artificial intelligence systems— which are built on historical injustices and dominance and prejudices—and really enable different types of code to be brought to the forefront, such as Indigenous AI.
Let’s create AI systems from an Indigenous perspective, from a different cultural lens, from an African lens, or Hawaiian lens, or a Māori lens. Not coming at it like, “okay, you’ve got to be diverse for the quota of diversity.” This will make systems better for everybody.
What about building solutions from us, the people? What would that look like? How would we actually go around decolonizing society? How would we go around decolonizing AI, and what would that look like? And that’s my work that I’m embarking on.
Mark: So, to bring in wider data sets that express a full picture of society, is that another way to say it?
Karen: Yes! Holistic. Total. Authentic. Representative. Something which is reflective and authentic of the world in which we live.
Mark: OpenAI is in the news almost every day, and they announced recently their video generator called Sora. Some of the early imagery is phenomenal. Google recently announced that it is pausing image generation. Inaccurate historical context was coming out of Google.
I’d welcome your thoughts.
Karen: Let me just backtrack a little, with the writers’ strike in America. That happened because Hollywood and the studios were exploiting people’s rights. Their data, their digital data, their digital identity.
Everybody is nervous about AI taking their jobs, wherever you are, whether you’re a driver, whether you’re an artist like myself. AI is reflective of society.
So with the writers’ strike, the studios tend to be quite exploitative of talent. What they were trying to implement through the contracts was also exploitative. So it’s very important for our society to reflect the best part of ourselves, because the Algorithm will automate whatever we train it.
Technology reinforces inequality. And when it does that, it’s not a glitch. It’s a signal that we need to redesign our systems to create a more equitable world. And so, as we’re moving forward in this ever-changing world to whatever role is being lost and whatever jobs are being discovered, it’s really important that it’s a world which is accessible for all of us.
And in terms of Gemini AI, that was the other extreme of bias in AI, where it was too diverse. There were Nazis, where they generated images that were Asian women or Black men. So it wasn’t historically accurate. So that’s why they paused it.
There’s got to be this middle ground—we’ve gone too far one way in terms of bias and too far one way regarding data sets in terms of diversity—to find something which is more representative.
And that again, is probably where the Indigenous AI and that decolonizing will create a bit more of an authentic representation.
Mark: Yeah, I don’t know how one really regulates it or oversees it. Other than the market going, “good tool / bad tool.” Where is that authentic voice to say, “this whole market’s moving in the right direction?”
Karen: That position of good or bad, that just comes down to perspective. That’s why we’re going to move into the age of perception and greater understanding. Because we’re in a time now of real division, and we’ve got to understand that what you may deem good, someone else might deem bad.
And that’s why, by democratizing more AI, more people can develop their own, more independent systems. So that people can have and code whatever they need to. They’re not dependent on a body doing it. Like, say, Joe Biden, two weeks ago. They’ve announced this organization now that’s going to regulate AI. But we don’t really know whose interest they’re actually going to represent, because there’s this history of governments and big business working together.
So that’s why what’s good for someone may not be good for you. It’s about us having a seat at the table of what’s happening.
Mark: Look 5-10 years out in AI. Love to hear your view of how the next few years play out in the world of AI.
Karen Discusses Her View of What’s Next from the Perspective of a Time Traveler from the Future
***
Karen invites us to envision a future where we have already created the world we would like to live in, using technology. What does it look like? Now, work backwards. What steps do we need to take today to get there?
I was inspired by her words: “The future is not something that happens to us. It’s something which we build together.”
I believe AI will be a force multiplier for human potential. To realize this, AI must be combined with our capacity for compassion, justice, and ethical behavior—our humanity, in a nutshell. AI will herald a new era of prosperity if—and only if—we prioritize the humanist impact of technology. Let’s apply AI for the betterment of our world and use it to help us solve our greatest, most pressing challenges. Let’s use it to become more human, not less.
And never forget: the future needs you today.
Thank you, Karen Palmer.
The comments of Karen Palmer are her own and do not necessarily represent the views of Open Text Corporation or its employees.
Success in Application Delivery Management (ADM) hinges on the ability to adapt to evolving technologies and methodologies. As we get into the swing of things in 2024, three key strategies emerge as essential for thriving in this area: embracing automation, prioritizing performance monitoring, and cultivating a culture of collaboration. Let’s dive into each of these tips and explore how they can empower you, as an ADM leader, to excel in the year ahead.
What are your predictions for application delivery in 2024?
In application delivery, automation serves as a force multiplier that can enable you to streamline processes, enhance efficiency, and drive innovation. By leveraging automation tools and frameworks, your team can automate repetitive tasks such as code deployment, testing, and infrastructure provisioning, freeing up valuable time and resources for strategic initiatives.
Automation not only reduces the risk of human error but also accelerates deployment cycles, allowing your team to deliver features and updates to end-users faster. Moreover, automation fosters consistency and repeatability, ensuring that deployments are executed reliably across different environments.
In 2024, the importance of automation in ADM cannot be overstated. Whether it’s through the adoption of CI/CD pipelines, configuration management tools, or infrastructure as code practices, your team must embrace automation as a cornerstone of your ADM strategy to remain competitive in today’s fast-moving digital environment.
2. Prioritize performance monitoring.
In an era where user experience can make or break an application, performance monitoring emerges as a critical aspect of ADM. Your organization must implement robust performance monitoring and management solutions to gain real-time visibility into application performance, identify bottlenecks, and proactively address issues before they impact end-users.
Continuous monitoring allows your ADM team to track key performance metrics such as response time, throughput, and error rates, enabling them to optimize resource utilization and enhance scalability. By detecting and resolving performance issues in real-time, you can ensure a seamless user experience across diverse environments and devices.
Furthermore, performance monitoring provides valuable insights for capacity planning and resource allocation, enabling your team to scale your infrastructure dynamically to meet changing demands. In 2024, prioritizing performance monitoring will be essential if your team plans to deliver high-performing, reliable applications that delight users.
3. Cultivate a culture of collaboration.
Application delivery is an interconnected world, and success relies on the ability to break down silos and foster collaboration across development, operations, and security teams. By cultivating a culture of collaboration and shared responsibility, your team can accelerate time-to-market, improve quality, and mitigate risks effectively.
Embrace cross-functional collaboration and encourage open communication and knowledge sharing across teams. By involving stakeholders from different disciplines early in the development process, you can ensure that applications are designed, deployed, and maintained with security, scalability, and reliability in mind.
Furthermore, fostering a culture of collaboration will enable your team to adapt quickly to changing requirements and market conditions, facilitating agile, iterative development cycles. If you prioritize collaboration, your team will be better equipped to navigate the complexities of ADM and deliver value to your customers more effectively.
Streamline and optimize to deliver better applications faster
Embracing automation, prioritizing performance monitoring, and cultivating a culture of collaboration are essential strategies for success in ADM in 2024. By adopting these principles, you can streamline processes, optimize performance, and drive innovation, empowering your team to deliver exceptional digital experiences to your users and stay ahead of your competition.
HIPAA taught us important lessons on how we interact with healthcare data, but it was a global pandemic that forced us to collectively go to data grad school.
Understanding where data lives and how we interact with this massive amount of information helps to unlock quality of care, interoperability between disparate systems and mitigate downstream information bottlenecks. This ultimately leads to more efficient revenue cycles. Healthcare accounts for an astounding 30% of the world’s data volume – and growing. The sector’s compound annual growth rate is expected to reach 36% by 2025.
The complexity of healthcare data shows no signs of slowing down. It’s no surprise the global healthcare big data and analytics services market is projected to increase to more than $13 billion U.S. dollars by 2025.1
Disconnected systems and siloed data keep most healthcare organizations from optimizing patient engagement. By connecting information to drive more informed and comprehensive health and wellness lifestyles, healthcare providers can offer effective and engaging digital experiences that align with patient preferences and move patients towards improved outcomes.
With more patient care moving from in-person to digital, it is important to create consistent and comfortable experiences for providers and patients across the continuum of care. But patient and organizational data is rarely integrated and accessible enough to drive intelligent, personalized and efficient digital services, which is affecting retention and loyalty. The same is true among healthcare payers, as they try to improve member experience and reduce churn. While content is abundant, organizations struggle to turn existing information into actionable data to drive patient engagement and desired outcomes.
A world-class digital experience is a priority for every health organization focused on embracing new digital patient engagement strategies which lower the cost of care, increase healthcare quality, and improve patient experience and member engagement. Healthcare organizations are trying to help individuals move towards a more informed and comprehensive health and wellness lifestyle and are helping to manage individual health challenges with informed and inspiring communications. A member 360 view supports content and context to communications that create intelligent, personalized experiences, catered directly to the individual to improve understanding, adherence, and impact.
Data is at the root of all patient experiences – in fact, it’s what separates the extraordinary from the ordinary. I’m thrilled to be attending the Healthcare Information Management System Society (HIMSS) conference to dive into this topic in a Breakfast Briefing on March 12 at 7:15AM in Room 203C.
Start your day with us as we delve into understanding the systems where data lives and leveraging the power of Artificial Intelligence (AI) to unlock and access data across the healthcare continuum. I’ll be joined by two leading healthcare organizations: Beth Israel Lahey Health and National Healthcare Group of Singapore for an engaging discussion about how they’re leveraging data to deliver world-class care. Beth Israel Lahey will also share some lessons learned around efficient access to data and how it helped improve utilization of their EPIC EMR system.
Gain insights to up-level patient experience
Save your spot – register now for the breakfast briefing for insights on how to uplift your healthcare operations and set the tone for an impactful day at HIMSS 24.
Statista, Global big data healthcare analytics market size by application 2016 & 2025.
If you’ve invested in Microsoft® 365 to help employees create, share, and collaborate more easily, you’re in good company. The organization reported monthly Microsoft® Teams users reached 320 million in FY24 Q1, up from 300 million the previous quarter.[1]
While Microsoft 365 has certainly earned its keep as a must-have productivity tool, it’s probably not the only platform powering your business—and not the only place content is being created and used.
With employees across R&D, manufacturing, engineering, marketing, and sales relying on various line-of-business applications, such as SAP® S/4HANA, Salesforce®, SAP® SuccessFactors®, or Microsoft® Dynamics 365™, the result is an explosion of content—and individuals caught in an endless loop struggling to find information.
Bringing together OpenText™ and Microsoft allows information to flow seamlessly across Microsoft 365 to unlock efficiencies across all areas of the business, provide information in context, and help organizations get the most out of IT investments. Let’s explore how OpenText Business Workspaces make it happen.
Fueling productivity tools with smarter information
While employees may rely heavily on Microsoft 365, they also need content from other apps and processes outside of this system. According to a Gartner survey, 40 percent of digital workers use more than the average number of applications (11), and five percent use 26 or more applications at work.[2]
With information siloed across applications, it’s no surprise employees struggle to quickly access content. This content chaos impacts employee experiences, operational efficiency, and business outcomes, with a recent Foundry Research survey showing that 58 percent of organizations have lost business opportunities due to an inability to access data in a timely manner.[3]
So how can organizations bring order to the content chaos running rampant within Microsoft 365? The answer: OpenText™ Business Workspaces.
Elevating productivity tools with OpenText and Microsoft
Business Workspaces are essentially content hubs within the Microsoft environment. These hubs bring together content, data, people, and tasks related to a project, case, or specific business goal. The result: contextually rich Business Workspaces that create a single source of truth across systems and tools to help users boost productivity.
While OpenText Business Workspaces make it simple to organize content and tasks, the advantages don’t end there. By putting AI into the hands of business users with an AI content assistant, content discovery and use becomes more efficient and intelligent.
Users gain new ways to interact with content, leaning on AI to navigate within desired Business Workspaces, easily summarize documents and extract insights to gain a deeper understanding of content. Plus, OpenText Content Aviator continuously learns from user interactions, making content experiences even more accurate and personalized over time.
Creating more business value through smarter information
OpenText solutions for Microsoft take the simplicity and familiarity of working in Microsoft 365 and apply smarter information management to bridge information gaps and create a consistent, trusted single source of truth. Through enterprise application integrations, users gain all the relevant content needed to do their jobs within the productivity tools they use every day.
With smarter information, organizations can solve four key challenges to deliver more business value:
Improve findability:Provide employees with fast access to easy-to-digest and relevant information
Tame content chaos: Streamline content creation and management across the lifecycle to control sprawl and content disconnected from business process.
Reduce risk: Apply role-based permissions and information governance to minimize data leaks and protect sensitive information.
Break down barriers: Bring relevant information from leading ERP and CRM applications, such as SAP and Salesforce, right into Microsoft 365 and Teams.
And, with OpenText AI solutions, organizations can leverage the full strategic value of data faster across diverse sources, with insights to help employees make data-driven decisions to predict and act on business opportunities.
[2] Gartner® Press Release, Gartner Survey Reveals 47% of Digital Workers Struggle to Find the Information Needed to Effectively Perform Their Jobs, May 10, 2023
[3] Foundry Research sponsored by OpenText, MarketPulse Survey: Digital Friction, September 2023
February 2024: What’s new in OpenText Intelligence CE 24.1
OpenText™ Core Intelligence
Hosted SaaS BI service now available on OpenText Cloud
With 24.1 we are launching a new service currently called OpenText™ Core Intelligence—Public Cloud which is an elastic, multi-tenant, SaaS offering that enables data-driven organizations to define, centrally deploy, and seamlessly embed metrics as well as interactive reports, dashboards, and self-service BI capabilities into any application to empower its users with answers, insights, and application automation. There were so many details to explain that we created a separate blog post here.
OpenText™ Intelligent Classification
Beta version of new Document API
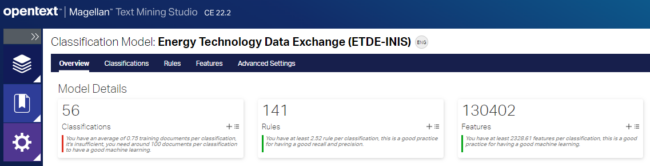
For 24.1, Intelligent Classification is combining forces with other OpenText product capabilities to provide a super service. The service is in Beta and includes a new Document API that provides a single entry point to extract content and metadata from a document. Behind the scenes, the API evaluates the document and makes decisions on which models, libraries, and processes are needed to detect and classify the document.
External LLMs for entity extraction
You can now use externally created Large Language Models (LLMs) for entity extraction—this backend service for refactoring external models supports multiple LLMs, including T5 models for Generative AI-based entity extraction and question-and-answer creation. This allows you to create custom LLM solutions based on your unique business requirements.
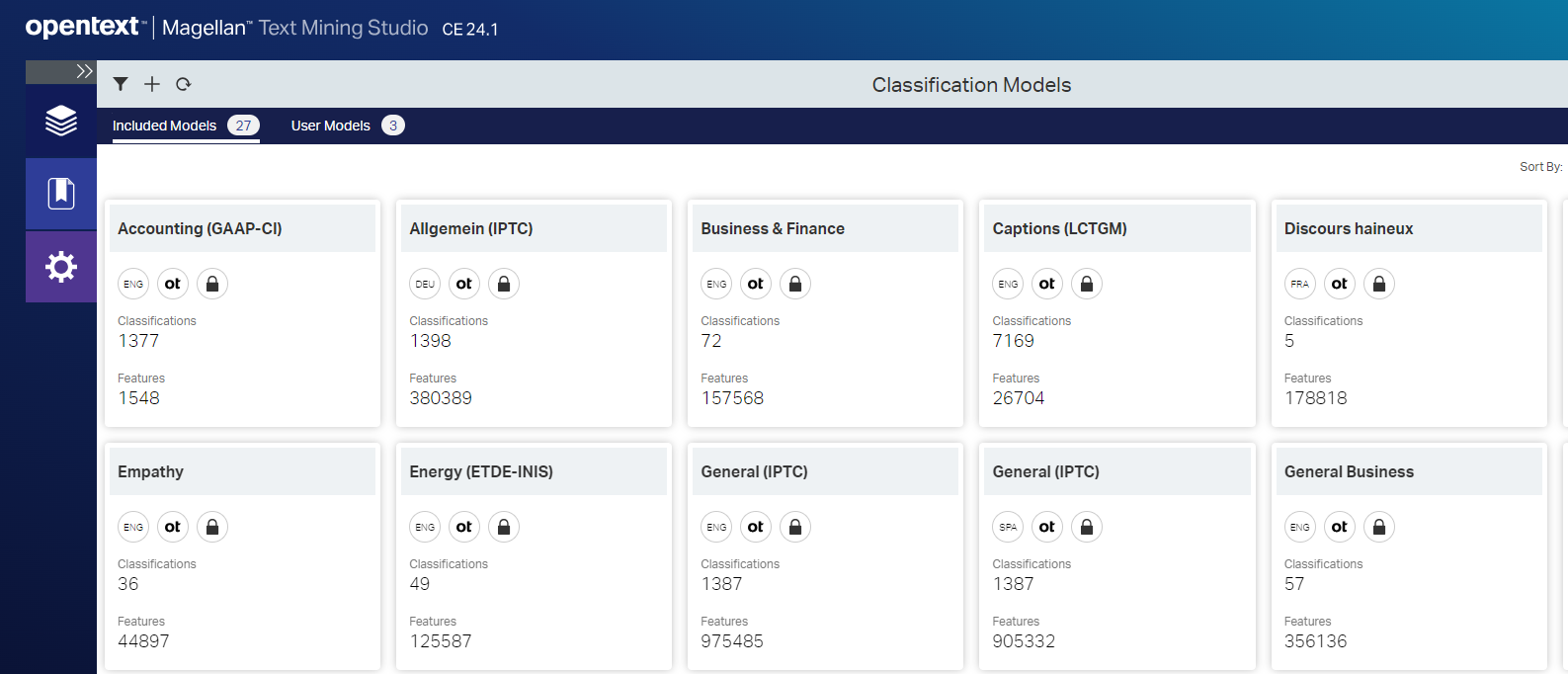
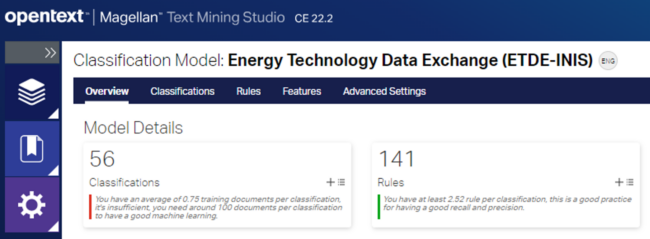
OpenText Magellan Text Mining Studio CE 24.1 showing grouped classification models
UI/UX enhancements
There have also been several UI/UX enhancements, including a single interface for both out-of-the-box models and externally linked Large Language Models (LLMs). The Magellan Text Mining Studio has also been improved in this release, adding a new view of sentiment analysis results in the profile testing section, and new grouping capabilities of text classification models through cards.
OpenText™ Magellan™ Risk Guard
Image analyzer upgrade
Magellan Risk Guard’s ability to uncover risky or sensitive content in images has been enhanced for CE 24.1. This includes updates to the existing image analysis models and UI labels, plus new image analysis models for medical imagery and offensive gesture detection.
OpenText™ Magellan™ Integration Center
Access to more data, faster
OpenText Magellan Integration Center provides data integration and data migration seamlessly across the enterprise. For 24.1, we now support read/write operations from BLOB storage containers including HDFS and S3 as well as several Web UI improvements in the Magellan Integration Center web user interface to match the existing functionality of the on-prem interface.
Bulk load from Parquet files
Apache Parquet is an open-source, column-oriented data file format designed for efficient data storage and retrieval. It provides efficiency and enhanced performance to handle complex data in bulk. This release includes a new Vertica driver that supports the bulk load of data from these Parquet data files, either from local storage or cloud storage like Amazon S3, into Vertica improving the speed and efficiency during the load process.
OpenText™ Data Discovery
Improved automation and efficiency
OpenText Magellan Data Discovery, as its name implies, is our tool for performing data discovery, advanced analytics, and predictive analytics on even the largest datasets, with minimal effort and drag-and-drop simplicity. For 24.1, the theme was to improve automation support for developers integrating analysis and to make it easier and more efficient to analyze data for the users. To support that theme, CE 24.1 includes several new REST API methods to improve automation support, including executing analysis, getting folder content, and exporting analysis using API calls, making it easier to include these artifacts in existing business processes.
New data source transformation commands
There are also several new transformation commands that allow you to work with data sources, such as creating indexes or table links, directly in the Data Discovery interface, saving you time from switching applications.
Get to analysis faster with pattern-based file loading
A new pattern-based file loading feature makes it more efficient to ingest data based on patterns in the file name, like sensor or IoT files that have similar date/time stamps in the file name.
Get a personalized demo of the full, composable OpenText Analytics and AI platform, or just the solutions of most interest to you. Discover everything you need for your AI transformation—from unstructured analytics and data lakehouse to BI, reporting, automation, and search. Book a demo today!
May 2023: What’s new in OpenText Intelligence CE 23.2
OpenText™ Intelligent Classification
Regrouped classification profiles
In Intelligent Classification CE 23.2, several UI/UX improvements and performance enhancements are designed to enable faster insight generation. One of those features allows you to configure text mining tasks faster by making it easier and faster to navigate classification profiles. In text mining terms, profiles are custom or out-of-the-box configurations aimed at a variety of text mining tasks. Over time, the number of these profiles can grow in quantity making navigating them difficult. In this release, the Intelligent Classification Studio user interface has been enhanced to support regrouped profiles allowing users to easily search and navigate through multiple profiles.
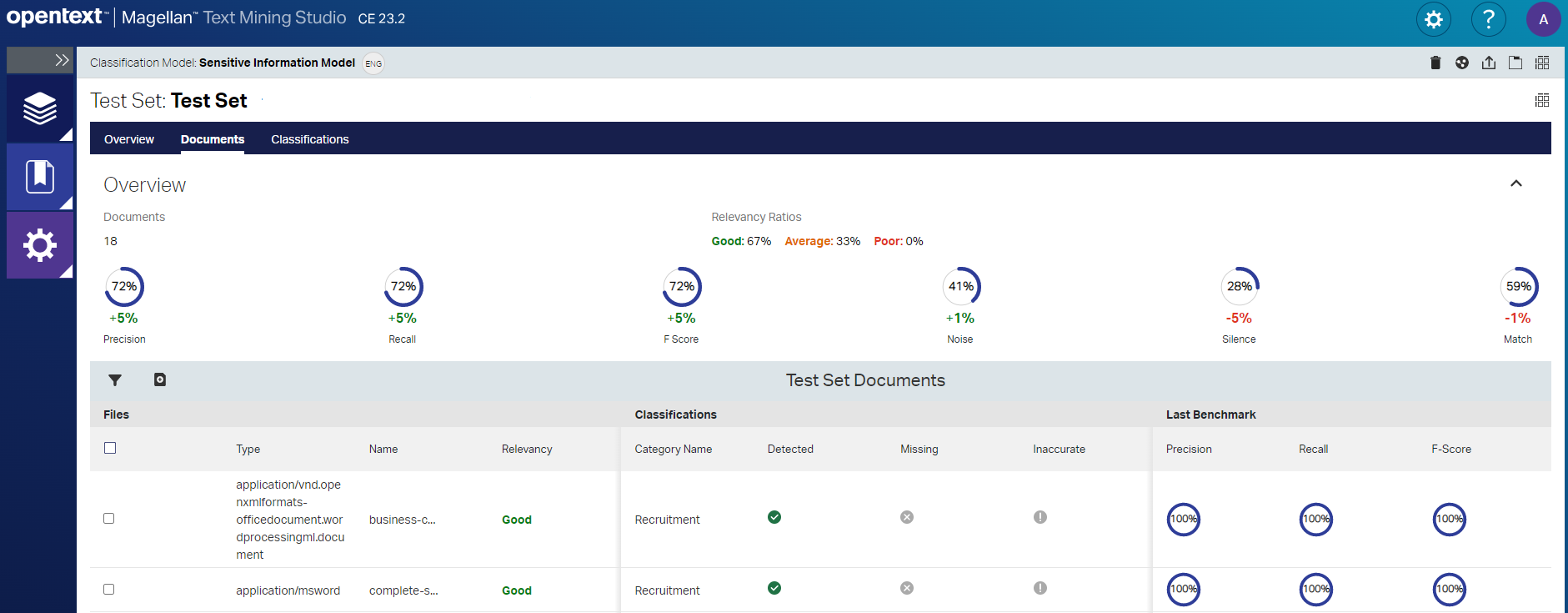
OpenText Magellan Text Mining Studio CE 23.2 overview showing classification model statistics
Improved model statistic navigation
This version of Magellan Text Mining also comes with an improved experience to better navigate through a model’s statistics. This allows less experienced users to interpret classification results and make better decisions regarding the next course of action like focus on precision, recall, a specific classification, or what to do with incorrectly classified documents.
Machine learning model training performance
There have also been significant improvements to machine learning model training performance allowing users to train classification models in a much shorter time to derive high-quality insights faster. Users can train complex classification models with 10-20 thousand annotated sample files in under 1 hour.
New pre-processing rules
Pre-processing rules help to better prepare raw input for text mining tasks and thus guarantee more accurate results. In 23.2, new rules for upper case sequence pre-processing and contract file cleaning are introduced in Magellan Text Mining Studio. These rules can be cloned and modified according to your specific content scenarios.
OpenText™ Magellan™ Risk Guard
OpenText Magellan Risk Guard CE 23.2 headless REST API
Headless sensitive data discovery services
OpenText Magellan Risk Guard is the AI-driven sensitive data discovery software that allows businesses to uncover risky content. In CE 23.2, new services allow developers to interact with the backend of Magellan Risk Guard through headless API calls, that is the communication path between an application and OpenText Magellan Risk Guard. This expands the integration capability with any desired workflow or external application requirement.
BETA Risk Guard for SaaS
Also in 23.2, the work on OpenText Magellan Risk Guard for Google Cloud Platform is progressing ahead of a SaaS offering. Risk Guard is providing customizable APIs for easy integration within any application. This first SaaS offering allows you to annotate files to validate if there are any PII and classify image and text according to sensitive information taxonomies. This version will also provide users with modifiable profiles to select the models and postprocess the results of annotation and classification according to their SaaS business scenarios.
OpenText™ Magellan™ Integration Center
Cloud deployment support
OpenText Magellan Integration Center is used to integrate and migrate data seamlessly across the enterprise as well as assist in automating processes. This release will support containerized deployment on Azure Kubernetes Service (AKS) and Google Kubernetes Engine (GKE) for self-managed hosting as well as OpenText Cloud managed service providing single tenant deployments.
Web Administration Console enhancements
A web administration console introduced in a prior release received a few new enhancements including grants administration where you can get and modify permissions directly in the web console and support for exporting your repository.
Expanded connectivity and platform support
Enhancement to the OpenText Content Server REST connector include scalability and performance improvements and also includes new support for moving objects and delete operations using the REST API. There is new platform support for releases of Oracle Linux (9.0, 9.1) and RedHat Enterprise Linux (9.0) and newly updated connectivity for various releases of OpenText Content Server (23.1), OpenText InfoArchive (23.1), Microsoft SQLServer 2022, PostgreSQL (15.1, 15.2) and OpenText Directory Services OTDS (23.1).
OpenText™ Data Discovery
Multitenant deployment support
Magellan Data Discovery allows business users and analysts to quickly access, blend, explore and analyze data with no complex data modeling or coding required. In this release, Magellan Data Discovery supports multitenancy allowing customers to have different groups of users sharing resources isolated from the other groups in the same instance of Magellan Data Discovery. This means different groups can share information and analysis inside a tenant but users will never see other tenant users or their information, or even know that other tenants exist. This is a step forward towards a full SaaS cloud offering for Magellan Data Discovery.
Improved exporting/sharing of analysis
Exporting from one server to another has been improved allowing Data Discovery users to export analysis from one instance, like a development server, and import into another, like a production server. Previously, analysis could only be shared between users of the same instance. Export import functionality has been modified to allow a password when creating the export file, that will need to be provided when importing the file. This will provide Magellan Data Discovery users more flexibility and capabilities when using and sharing analysis.
OpenText™ Intelligence
WCAG 2.1 AA accessibility certification
OpenText Magellan BI & Reporting is the enterprise-grade BI platform that generates, manages, and securely delivers data-driven information assets at enterprise scale. To promote inclusivity, several projects have been ongoing to deliver an accessible report viewing experience, empowering users living with a wide variety of visual, motor, cognitive, and other disabilities to consume reports effectively. For this release, we have officially received Web Content Accessibility Guidelines (WCAG) 2.1 AA accessibility certification.
The certification applies to both web-based report viewers—the Standard Viewer and the Interactive Viewer—including cases where they are embedded into third-party applications using the JavaScript API. The certification applies to keyboard navigations and shortcuts, screen reader support, chart patterns, marker contrast support, descriptive captions, and alternate text. The certification was conducted on version 22.3, so that versions of the Analytics Designer and higher are certified to author WCAG 2.1 accessible reports.
February 2023: What’s new in OpenText Intelligence CE 23.1
OpenText™ Intelligent Classification
Integrate externally created classification models
The shift to utilize external classification models, like open-source transformer-based BERT models, within Magellan Text Mining allows you to leverage the treasure trove of preexisting models through both the API and now the UI. This innovative new approach allows you to combine existing OpenText composite AI models with BERT models providing an increased level of content classification.
Sentiment analysis extended to include empathy detection
A new machine learning model to detect empathy, like feeling anxious or growing impatient, combined with the existing models to detect emotion, tonality, intention, and hate speech provides a complete understanding or your customer, citizen, or employee generated content. This natural language understanding model is useful for profiling user generated content such as comments, blogs, chats, etc. The new empathy model includes the following classifications:
Empathetic concerns
Personal distress
Bad Mood Bad Shape Demotivated Feeling Anxious Feeling Bad Feeling Depressed Feeling Fear Feeling Guilty Feeling Lost Feeling Miserable Feeling Pain Feeling Sad Feeling Worried Feeling Sorrow
Deserve Diagnosed Feeling Sick Frustrated Growing Impatient Hard Time Inaccurate Insane Insults Irritated Not Working Pressure Something Crazy Something Wrong Stressed Trauma Uncertainty Unjust Waste of Time
New empathy model classifications
Granular benchmarking service for text classification models
Data Scientists and Computational Linguists need tools to fine-tune classification models. Detailed metrics showing the accuracy of a model for each document and for each classification allow them to focus on the area of the taxonomy where precision or recall issues must be addressed. By looking at the problematic areas in the model, the users can make informed decisions on how to improve accuracy. For example, they can quickly identify 4-5 classifications with a lower recall and decide to add more training exemplars to the model or build the rules to trigger classifications based on key phrases found within text. With Granular Benchmarking, not only the modelling, but also the presentation of the classification results is made clearer and comprehensible.
New scriptable connectivity platform
The Scriptable connectivity platform allows Magellan Text Mining Studio users to build Python scripts to access the content that was previously not available for analysis without building new connectors. The option to build Python scripts directly within the studio is not only a time-saver but the users now have control over connectivity scripts allowing them to easily re-adapt those scripts for new content repositories.
Automatic rule creation based on classification name
Building deterministic rules in a model is a time-consuming exercise, but it always begins with the creation of a basic rules layer. An automated, one click, procedure to generate the rules based on the taxonomy labels helps users to create that basic layer without manipulating large XML or JSON files. Once the rules are created, the users can immediately start classifying the content and with the automated process the users can quickly tag the content to build training sets.
OOTB Pre-processing rules for email segmentation
Pre-processing rules help users to remove the portions of the input text that have no value for text mining. For example, the user can automatically remove email signatures or any text that is not directly related to the body of the email. These new pre-processing rules for email segmentation can be cloned and modified with additional key words and key phrases to further refine this pre-processing step.
OpenText™ Magellan™ Integration Center
New document transformation capabilities
Version 23.1 of Magellan Integration Center includes a few new document transformation capabilities including the ability to merge multiple files in PDF, TIFF formats into a single document and a new system function that can converts .doc and .docx and TIFF files to PDF.
New Integration Center Web Admin Console
A new web administration console has also been released in version 23.1 and includes many features previously only available in the desktop client. Some of these features include the ability to create repository entries, add, delete, or update server hosts and client hosts, declare services, define applications that a client host can use, add or update users and more… all the from the browser.
OpenText Magellan Integration Center Web Administration Console CE 23.1
Content Server REST API connector enhancements
With this release there are several improvements to the Content Server REST API connector including URL creation support for Content Server or xECM repositories, the ability to perform record management classification, and several enhancements with the artifact copy operations.
OpenText Core Content connector
A new two-way connector to OpenText Core Content is now bundled with Magellan Integration Services providing access to this content store.
OpenText™ Magellan™ Risk Guard
Support for bulk classification model import tasks
Users can browse existing classification models and select all or several classifications to expose at once within Risk Guard user interface. This feature helps to customize the models available within Risk Guard much faster and makes that task more convenient.
Metrics to validate the usage of Magellan Risk Guard
Users can rely on the size of the files that were processed in MRG project and browse those from metrics. This feature allows users to better plan Risk Guard tasks.
Processing of German PII/PSI content greatly expanded
The availability of German PII/PSI models in Risk Guard along with the expansion of the dynamic linguistic profile for processing German content opens up Risk Guard to organizations needing to evaluate German content for sensitive or risky information.
August 2022: What’s new in OpenText Intelligence CE 22.3
OpenText™ Magellan™ Risk Guard
Discovery of files with sensitive data related to specific data subjects
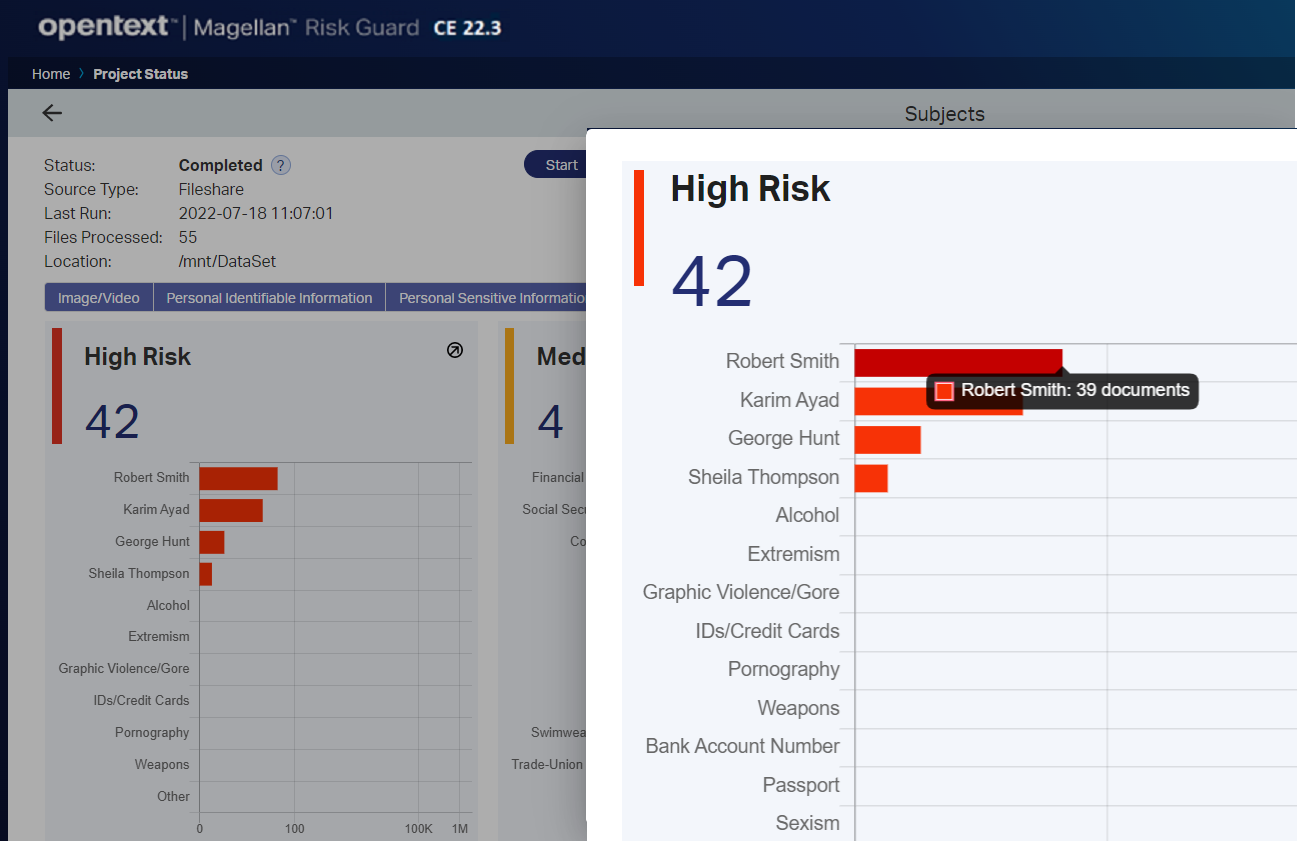
Business users can support compliance with consumer and employee privacy regulations by discovering and taking action to protect potentially risky files related to specific customers or employees. This enables users to easily create a Magellan Risk Guard risk assessment dashboard for specified data subjects.
In this example, an HR admin can assess a broadly available file share for content with sensitive data related to specific employees, so that high-risk files can be moved to a more secure content repository.
New UI capability to customize the discovered risks in built-in reporting
Information security, privacy management and compliance teams can optimize their sensitive data risk assessments by including only the most relevant risk types for their project, company or industry. With this update, it is simple to use the Magellan Risk Guard UI to select or de-select risk types. The risk-type customizations will automatically be applied to the built-in dashboards and reports.
Via simple checkboxes, users can select and de-select risk types to customize the built-in reports and dashboards.
OpenText™ Intelligent Classification
New UI capability to add dictionaries to use with Magellan’s composite AI models
Data scientists and business analysts can more easily support text analytics use cases that require their own controlled vocabularies. With this Magellan Text Mining update, users can self-service add or customize dictionaries to use with AI models.
OpenText™ Data Discovery
New supported drivers for ingesting data
Create insights and conduct advanced analysis on 13 new data sources including MySQL, Oracle, SQL Server, Salesforce, and even the files and sensitive data risks identified by Magellan Risk Guard.
OpenText™ Intelligence
Security updates, including an upgrade from Apache Axis 1 to Axis 2
Information security and IT teams can support data security by upgrading to Magellan BI & Reporting version 22.3. This update includes thousands of security enhancements as part of Magellan’s commitment to proactively upgrade the underlying third-party components.
New deployment option for Google Kubernetes Engine (GKE)
IT teams can now select from more deployment options to address a broader set of cloud deployment requirements: Google, Amazon and Microsoft Kubernetes services.
June 2022: What’s new in OpenText Intelligence CE 22.2
Magellan Risk Guard
AI-powered risk analysis reporting for OpenText™ Extended ECM and Documentum: Business users can accelerate compliance by quickly creating custom interactive reports without needing AI, data science or analytics expertise. This update enables users to customize their analysis of content in Extended ECM or Documentum by creating interactive PII and PSI reports that are integrated into the Magellan Risk Guard user interface (UI). To learn more, read the blog post about the new reporting capabilities.
Business users can select a pre-built report from the top navigation and then customize the report by using a simple menu.
User delegation management: Information security, privacy management and compliance teams can secure and limit access to the content risk assessment results available in the Magellan Risk Guard UI. With this update, end-user roles can be set up and managed in compliance with each organization’s information governance policies.
Intelligent Classification
Model design recommendation for dictionary and text classification: Data scientists and business analysts can create and customize natural language processing (NLP) more quickly with the simplified NLP modeling experience in the 22.2 release. The updated intuitive experience includes recommendations based on an assessment of the model’s classifications, rules and features so that the user can focus on needed optimizations.
Intuitive assessment and recommendations are available for optimizing NLP models.Intuitive assessment and recommendations are available for optimizing NLP models.
March 2022: What’s new in OpenText Intelligence CE 22.1
The latest updates include democratized risk analysis, new text mining models, expanded language support, and external ML model integration.
OpenText™ Cloud Editions (CE) 22.1 features exciting updates across the OpenText enterprise applications ecosystem, including significant enhancements to our AI and Analytics products below:
OpenText™ Magellan™ Risk Guard
OpenText™ Intelligent Classification
OpenText™ Data Discovery, Cloud Edition
OpenText™ Magellan™ ML Model Management
OpenText™ Magellan™ Integration Center
OpenText Magellan Risk Guard
Organizations need a way to find out what risky or sensitive information may be within their enterprise content repositories. However, each organization has unique requirements driven by their operations.
In the 22.1 release, OpenText Magellan Risk Guard has new innovations that make it easier to tailor the application to business operations. By addressing many common requirements, these built-in capabilities reduce the time, effort, and services needed to customize Risk Guard.
Configurable user roles and permissions
To democratize content ownership and risk analysis, OpenText Magellan Risk Guard 22.1 provides configurable roles and permissions allowing individual users to analyze their content and manage their own risk assessment projects.
Remediation actions for OpenText Documentum
In addition to using OpenText™ Documentum™ as a content source for analysis, you can now take remediation action as well. In this release, you can copy, move, or delete content across broader content stores, including Documentum.
French UI support
In our efforts to make content risk analysis available to more users around the globe, the Magellan Risk Guard user interface is now available in the French language.
Intelligent Classification
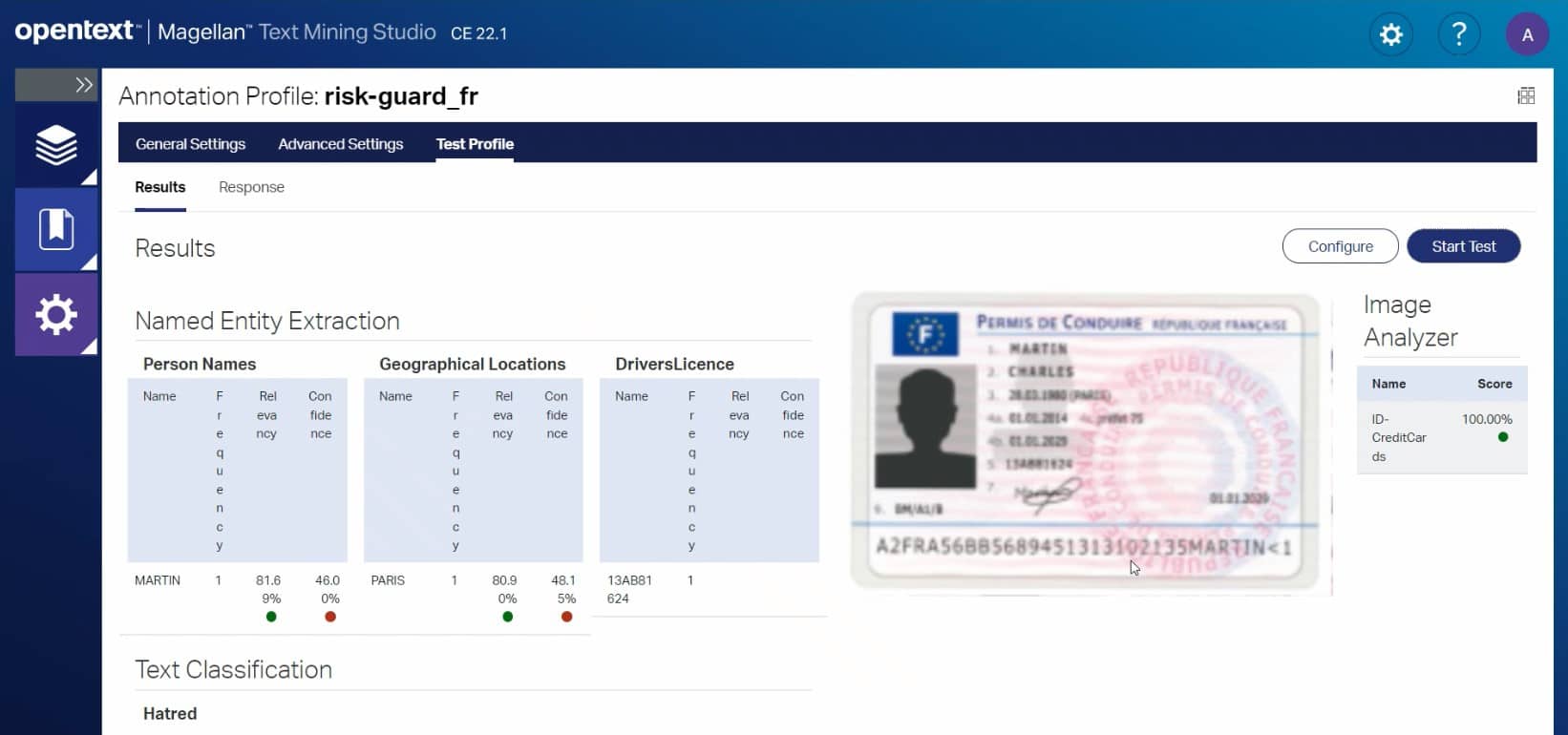
An example of the OpenText Intelligent Classification Studio showing the results of a named entity extraction of a driver’s license from France.
NLP and NLU models for French
Natural Language Process (NLP) and Natural Language Understanding (NLU) models are now available to analyze French language content.
OCR for non-searchable PDF
Some PDF files are constructed in such a way that the text embedded within the document is not searchable. This release of Magellan Text Mining provides OCR for these documents turning this previously unusable content into valuable insights.
OpenText Data Discovery
Scikit-learn model evaluation
New features in Data Discovery allow for the evaluation of scikit-learn models. End users can easily determine the state of a model with a graphical representation. Different measures are considered depending on the model type and can return results of valid, invalid, or degraded.
OpenText Magellan ML Model Management
Publish TensorFlow models in Magellan
Organizations need to be able to get insights from small datasets, which requires different frameworks. In the latest release, models developed in TensorFlow can be easily integrated into Magellan, expanding the availability of models within Magellan.
Enhancing usability of Magellan Risk Guard and other Magellan products, this release allows for broader connectivity to leading content sources, including SharePoint connector that includes token-based authentication, JIRA support, and Linux file share support.
Improved crawler performance and scalability
Enhancements improve the performance of the crawler enabling processing of large content and data sets.
Additional details on the latest updates can be found in the product release notes. Learn how to drive faster decisions, smarter models, and better results with OpenText Analytics Cloud.
OpenText™ Information Archive (InfoArchive) provides highly accessible, scalable, economical, and compliant archiving of structured and unstructured information. Whether actively archiving business information to reduce system loads or decommissioning applications to stand down outdated systems, InfoArchive is the flexible and cost-efficient way to reduce IT costs and accelerate the move to a modernized, cloud-based architecture.
February 2024: What’s new in OpenText InfoArchive CE 24.1
Expanded file formats supported in full-text indexing (experimental)
Full-text search was introduced as an experimental feature in InfoArchive CE 24.1. Indexing now supports over 1,500 file formats, including Microsoft 365, Office, PDF, and legacy formats for other applications.
Exports now include retention metadata
Exports can contain compliance information such as retention policy. Metadata configuration can be done via the web interface or by editing YML files.
Ingest SIP Packages directly from the user interface
Upload up to 10 SIP packages of up to 20MB each directly from the web console for faster and more convenient configuration testing in a demo or test environment. No command line is required.
Custom retention period for background searches
Configure how long to keep background searches after completion, changing the default from 7 days.
Name/value pair editor
The new name/value pair editor introduced to the form editor simplifies the management of multi-value controls for developers.
Export configuration through administrative interface
The export configuration XSLT template can be loaded, and minor modifications can be made directly through the user interface.
Helm charts have been revised and updated
Helm charts have been updated, and new Kubernetes platforms and versions are now supported.
October 2023: What’s new in OpenText InfoArchive CE 23.4
Full-text search (Experimental) for documents and attachments
The new, experimental, full-text search capability allows users to identify documents and attachments matching keywords in the archive. Create document sets for export for legal hold based on keyword searches.
Partition and secure retention policies
Retention policies are now protected through group permissions, avoiding confusion when managing a records policy across multiple applications and divisions in the organization.
Saved search exports, grouped by matter
Better manage complex exports with saved searches that can now be exported individually or grouped through matter.
Role management can now be application-dependent
Roles for users are now application-dependent to better manage oversight roles across a large archive.
Global Settings are now editable
Global settings are now editable.
Configure new exports through the user interface
Configure new exports through the Export Configurations tab under the administration page.
Sort search results on multiple columns
Sort search results on multiple columns simultaneously, making search results far more practical with large datasets.
Large-scale, generative AI models are opening up the possibility to do anything—from building applications to designing game-changing UI experiences. And as generative AI continues to make waves, its promise to revolutionize development and testing will usher in a new era of DevOps.
But with generative AI comes uncertainty and doubt, which casts a shadow on the potential of what AI can bring to your company’s development and testing teams. To help better understand AI’s potential value, here are four hidden benefits that generative AI brings to DevOps.
The traditional method of test creation is generally limited to the human capacity and understanding of test requirements. This often has unintended consequences.
Generative Al tailors specific content by recommending diverse test ideas and generating test scripts. This helps developers and testers alike reduce human errors. In cases where software needs to be tested across multiple platforms, devices, and configurations, auto-generating tests will help developers and testers reduce waste, downtime, and rework. The result will be countless hours of time saved.
2. Reduce costs
Reducing costs in DevOps generally requires making decisions that reduce complexity and mitigate risks. But the lack of insight from end-to-end hinders the decision-making process—all the way from the code level to the CEO level.
Generative AI helps your company make better informed, data-driven decisions by gaining high-value insight and rapid results into areas that enable you to mitigate high-value risks. Generative Al also cuts complexity by auto-generating tests, test scripts, and test cases, making your value stream flow more efficiently.
3. Enhance quality
Escaped defects have a way of finding themselves into releases and into the hands of customers. This often leads to a flood of support tickets from upset customers and multiple patches to fix the release.
With generative Al, developers and testers can find more defects early to ensure each release meets your company’s high standards of quality. Finding and resolving problems early with AI provides you with the potential to go to market faster while simultaneously helping your teams maximize test coverage.
4. Improve productivity
The repetitive manual process of creating tests can unknowingly make tests time-consuming and brittle. Broken syntax, random data, and external dependencies are all culprits that make tests inefficient.
Generative AI improves the breadth and depth of testing with AI models capable of breaking down silos with high-volume, diverse, and realistic tests. It enables DevOps teams to automate repetitive tasks, and empowers them with more time to focus on value generating work that will improve their overall productivity.
Overcome clout about generative AI
The best way to overcome the uncertainty and doubt about generative AI is to focus on the existing things that need to be addressed in your company and consider:
Would reducing human error, waste, downtime, and rework help you save time?
Would mitigating high-value risks and cutting complexity help reduce excess spending and costs?
Would catching defects early, getting to market faster, and maximizing test coverage help enhance your total quality?
Would automating repetitive tasks and letting developers and testers focus on value generating work help improve productivity?
If you answered yes to any of those questions, it’s time to reimagine work with AI.
At OpenText, we are pioneering this new era of possibilities where generative AI complements human creativity to become tomorrow’s solutions. We recently launched opentext.ai and are using AI to predict delivery times, identify risks and gaps, and generate AI-generated test scripts that deliver high-quality software applications at unprecedented velocity and efficiency.
Backed by next-generation LLM, OpenText gives organizations the ability to harness the power of generative Al without losing control of their sensitive and proprietary data.
Poland’s e-Invoicing Mandate proceeding in 2026. We hope.
The much-anticipated Polish e-Invoicing System (KSeF) is back on track. Poland was originally set to embark on their e-Invoicing journey at the beginning of this month, 1st July 2024. As you read in our last update, the implementation date was pushed back due to what we’ll diplomatically call ‘technical hiccups’.
In the aftermath of the announcement, there had been hopes that Poland would resolve the issues rapidly and reschedule the roll-out of e-Invoiding for 2025. It appears that was rather optimistic. Today, we have more clarity on the Ministry of Finance’s plans, or should we say, their latest round of sanguine predictions.
In a recent press briefing, the Minister of Finance, Andrzej Domański, and the Head of the National Revenue Administration, Marcin Łoboda, announced the phased introduction of the mandatory KSeF:
Starting from 1st February 2026, for taxpayers whose sales value in the previous year exceeded PLN 200 million. (Yes, you read that right, 2026!)
From 1st April 2026, for all other taxpayers. (No, this is not an April Fool’s joke, they are genuinely talking about rolling out the second wave on 1st April!)
This announcement provides businesses with a clear timeline to work towards, enabling better planning for the impending changes. Or at least, that’s the theory.
The KSeF Audit: A Comedy of Errors?
The decision to redesign KSeF was a response to the shortcomings identified in the audit. Minister Domański believes that the audit was crucial in averting potential disruptions to the Polish economy. The technical analysis revealed that the project’s lack of proper supervision and the system’s inadequately designed architecture resulted in low efficiency and a high failure rate.
We might therefore conclude that delaying until 2026 was to ensure there are no further embarrassments for the Ministry.
The draft law to postpone the KSeF implementation date is currently awaiting the President’s signature.
Now is the time to prepare. Probably.
The announcement of the KSeF implementation date is pivotal for all entities operating in the Polish market. While many taxpayers had already begun adapting their processes and IT systems to be KSeF-compatible and training their teams accordingly, with the announcement of the delay in January 2024 we saw many large companies drop their internal projects in dismay.
With a new implementation date for the system, it’s time to dust off those change management project plans and start again. It’s imperative that organizations start early to ensure that any changes required to their internal systems and processes can be managed effectively, minimizing the risk of errors and non-compliance with the new regulations.
If you anticipate significant IT or operational difficulties due to KSeF (especially for foreign entities registered for VAT in Poland), now is the perfect time to start discussions with external advisors and your internal project team on how to structure the implementation process (especially regarding future purchase and sales invoices workflow).
OpenText is ready to assist customers meet the deadlines above. Our e-Invoicing readiness check service is available to aid customers in assessing whether the output from their ERP, finance and accounting systems meets the requirements of the new legislation.
The good news is that our global e-Invoicing compliance platform is available and already successfully connected to the KSeF platform, so we are ready to deploy whenever you are and can support you through this transition.
Reach out to your OpenText account representative or contact us here.
February 2024
Poland’s e-Invoicing Mandate Postponed Indefinitely Due to System Errors
On 19 January 2024, Polish Finance Minister Andrzej Domański unexpectedly announced that the implementation of their proposed national e-Invoicing mandate had been postponed indefinitely.
This marks the second time Poland has postponed the mandate, having previously pushed it back six months from an original timeline of January 2024 to July 2024.
The KSeF system has been operational in a “voluntary phase” since January 2022, and businesses had been reassured by the Ministry of Finance that the KSeF system was ready for full implementation. This makes the recent discovery of critical errors and concerns about the platform’s ability to scale to the expected volumes of invoices all the more surprising. While the Ministry had previously claimed the system was capable of handling 100 million invoices per day, it appears that this figure may fall short of the actual demand due to peaks in processing on the first and last day(s) of each month.
Given the risk that businesses would be unable to issue invoices in the event of a system failure, the ministry has prudently decided to pause the mandate. A comprehensive external audit of the system is now planned to evaluate the issues and formulate a plan to resolve them. Only after the audit is complete and a remediation plan is in place will a new timeline be announced. The Ministry made clear that this will not be in 2024.
KSeF remains available on a voluntary basis
It remains unclear whether the Ministry will take this opportunity to address the already well-understood deficits in the KSeF system, such as the inability to include attachments with invoices issued through the platform. This common business practice is currently unsupported by the KSeF system, leaving businesses with the unenviable task of sending attachments separately via e-mail or other means, and buyers having to reconcile these attachments with the invoice received via KSeF.
Simultaneously, doubts have been raised about the compatibility of KSeF with the European Commission’s planned ViDA (VAT in the Digital Age) reforms. While ViDA has not yet been approved, it seems likely to proceed eventually, leaving Poland with a pressing need to adapt KSeF yet again to meet the demands of the reforms.
Although the Minister’s decision may be pragmatically welcomed as a step towards ensuring business continuity, it also comes as a blow to the many enterprises who have already invested in technology to connect to KSeF.
However, OpenText obtained confirmation directly from the Polish Ministry of Finance that: “KSeF still works in an optional version, and you can use it. Taxpayers can still integrate their financial and accounting programs with the National e-Invoice System.” In other words, KSeF is still available to be used on a voluntary basis as it has been since January 2022, and Polish companies can continue to roll out their e-Invoicing solution leveraging KSeF.
A unique opportunity to explore the benefits of e-Invoicing
As we all know, there are significant benefits in switching to electronic invoicing, in terms of reducing the costs and effort associated with manual invoice handling. This leads to faster payments, improved cash flow, and better customer and supplier relationships.
For suppliers sending invoices to their customers, there remains an obligation to obtain consent from your buyer to switch to electronic invoicing. However, the buyer does not need to establish a direct API connection to KSeF in order to receive their invoices electronically. They can register to manually download invoices from the KSeF portal in either PDF, XML, or HTML format. Multiple invoices can be downloaded together in ZIP format.
Buyers receiving invoices from their vendors can proactively provide consent in order to begin receiving their invoices. It seems likely that larger suppliers will be keen to proceed with automated e-Invoicing due to all of the business benefits.
OpenText Professional Services Community Survey can assist clients by finding out which of their buyers are ready to receive e-Invoices via KSeF, and which of their larger suppliers are willing and able to send e-Invoices.
Businesses should therefore see this as an opportunity, rather than a setback. As governments recognize the complexity of national e-Invoicing regimes, businesses too must understand that this is going to be more complicated than they expect. This is especially true for multinational companies with entities operating in multiple regimes affected by the impending mandates not just in Poland but also Romania & Malaysia (2024 mandates), Germany, Greece, Spain, and Slovakia (2025 mandates), and France, Belgium, Croatia, and Latvia (2026 mandates).
This wave of impending mandates will drive incredible demands on businesses to modernize and digitize their entire order-to-cash and procure-to-pay processes in a very short space of time, and in a manner that facilitates far greater agility. An agile and robust global platform for electronic invoicing will be an absolute necessity in order to meet the requirements of multiple national mandates in a very short space of time.
Poland’s “voluntary option”, therefore, represents a perfect low-risk approach to trying and testing your e-Invoicing strategy and platform in advance of the next major mandate.
August2023
Polish President signs legal act mandating the KSeF e-Invoicing system
On August 4, 2023, the President of the Republic of Poland endorsed an Act that introduces the obligation to issue invoices through the National e-Invoice System (KSeF). With the Act’s approval awaiting publication in the Journal of Laws, the final stage of the legislative process is underway. Once published, the Act will transition into a legally binding mandate, and the majority of its provisions will spring into action on 1 July 2024.
Presently, e-invoicing through KSeF is optional, coexisting alongside various traditional invoicing methods. However, the clock is ticking, and in less than a year (starting July 1, 2024), active VAT taxpayers based in Poland will be mandated to exclusively use KSeF for issuing invoices. This mandate will also extend to foreign entities possessing a fixed establishment within Poland’s territory, as defined by VAT regulations.
Prepare for the transition to the Polish e-Invoicing mandate
To ensure a smooth transition, the Ministry of Finance is preparing an information brochure detailing the final version of the FA(2) XML schema for e-invoices. In tandem, comprehensive technical documentation is in the works, encompassing critical aspects such as generating and managing collective identifiers for payments and QR verification codes.
We anticipate the release of the final versions of regulations outlined in the Act, notably concerning KSeF utilization and exemptions from the e-invoicing obligation. This transition will also prompt changes in other regulations, including those governing invoice issuance, as well as the precise scope of data to be incorporated in VAT-related tax returns and records. These regulatory adjustments aim to align existing frameworks with the requisites of e-invoicing. An initial step in this direction was taken on 7 August, with the publication of a draft amendment to the regulation governing KSeF usage.
As the clock ticks down to July 2024, businesses both within Poland and those with a fixed establishment on its soil need to gear up for the e-invoicing revolution.
OpenText Active Invoices with Compliance is already online and connected to the KSeF portal for customers wishing to prepare for the transition. In addition, our e-Invoicing mandate readiness check service is available to assist customers in assessing the output from their ERP/finance/accounting systems to ensure it meets the new legislation. Reach out to your OpenText account representative or contact us here.
July 2023
Polish legal wrangling around new e-Invoicing system
After the postponement of the mandate for e-Invoicing, the Lower House of Parliament in Poland (Sejm) passed an amendment to the VAT Act to support the plans for KSeF (the Polish e-Invoicing platform). However, the Senate voted to reject the amendment. This appears to be due to political conflict between the higher (senate) and the lower (Sejm) chamber of the Polish parliament.
Since the ruling party holds the majority of votes in the Sejm chamber they were able to overrule the senates rejection, effectively approving the KSeF legislation. The bill is now ready to be sent for final signature by the President in August 2023 with the intent to push forwards with the mandatory e-invoicing regime as from 1 July 2024.
February 2023
National e-Invoicing mandate postponed to July 2024
The Polish Ministry of Finance have completed a public consultation on new draft legislation surrounding mandatory e-Invoicing via the KSeF platform. The result of the consultation has been to postpone the implementation date of the mandate from 1st January 2024 until 1st July 2024, giving taxpayers a further six months to prepare. Penalties for non-compliance will come into effect as of 1st January 2025.
The draft legislation states that consumer invoices (B2C) will now be fully excluded from the scope of the mandate.
Further, a provision has been made for taxpayers to issue invoices outside of the KSeF platform in the case of technical failure on the taxpayer’s side as long as they are subsequently transmitted to the KSeF system the following day.
Finally, there is a public consultation on a new proposed schema defining the logical structure of e-Invoices. The specifications can be found on the website of the Ministry of Finance.
July 2022
New specifications for e-invoicing mandate released
The Polish e-invoicing is expected in 2024 so companies still have some time to prepare. Here are three important aspects of these new mandates.
Timeline and mode of inception
The Polish mandate imposes a “big bang” approach for both issuance and reception of e-Invoices. After an initial voluntary period, which already came into effect on 1 January 2022, the mandate comes into full force for all companies, regardless of size, beginning in the second quarter of 2023.
The exact inception date of the reform is not yet finalized, which, given the short lead time, is of course going to cause concern for companies operating in Poland. This lack of communication of an official date could lead us to suspect that the Polish system is still not fully ready – but only time will tell.