

OpenText™ Knowledge Discovery helps organizations make sense of complex, high-volume content while keeping it secure, governed, and ready for AI. As enterprises accelerate their AI initiatives, OpenText Knowledge Discovery continues to expand its enrichment, search, and deployment capabilities to support scalable AI Knowledge Discovery. Explore the full solution on the OpenText™ Knowledge Discovery product page.
April 2026: What’s new in OpenText™ Knowledge Discovery 26.2
OpenText Knowledge Discovery 26.2 makes rich media a first-class citizen in your AI strategy. This release introduces a generative AI module that automatically describes images and video frames, extends visual clustering to images, and brings Aviator Search to OpenText Private Cloud, so organizations can close the gap between the content they have and the insights they need.
Turn visual content into searchable, AI-ready intelligence
If your organization holds large archives of images, video footage, or broadcast content, you already know the problem: that content exists, but you can’t find, classify, or use it the way you can with text. It sits in storage, effectively invisible to search and AI.
The new image description module for Media Server changes that. Using multi-modal GenAI, it automatically produces rich text descriptions of images and video frames at the point of ingestion, without manual tagging. The result is visual content that is immediately searchable, classifiable, and ready to serve as grounding data for AI. For organizations preparing for GenAI initiatives, this removes one of the most persistent blockers: unstructured visual content that requires text for AI to read, index, or act on, making it effectively visible to any downstream model or search system.
Find connections across images and video at scale
Visual clustering, previously available for video, now fully extends to images, creating a single analytical layer across both content types. OpenText Knowledge Discovery can now automatically identify and group visually similar content across image and video assets in one pass.

Visual clustering of images using OpenText Knowledge Discovery
For investigators working through large volumes of visual evidence, connections that once required hours of manual review can now be surfaced automatically. For media organizations managing large image archives, it means duplicate detection, near-match grouping, and related asset identification without human intervention. For compliance teams dealing with visual content at scale, it means faster, more defensible workflows.
Most platforms search the text about an image. OpenText Knowledge Discovery now finds relationships within and across visual content itself, a meaningful capability for any organization where visual content is high-volume, manually unmanageable, or critical to investigative and compliance workflows.
Aviator Search is now available in OpenText Knowledge Discovery for Private Cloud
Aviator Search is now available as an integrated application within OpenText Knowledge Discovery for OpenText Private Cloud. With it, users can query across multiple repositories simultaneously – OpenText Content Management, OpenText Documentum Content Management, SharePoint, file system and other connected sources – using natural language, and receive consolidated answers without switching between systems or manually reconciling results. Organizations that have chosen OpenText Private Cloud for its managed, dedicated environment can access the same AI-powered search experience, without having to choose between operational simplicity and modern search capabilities.
If you’re running OpenText Knowledge Discovery on OpenText Private Cloud, this means conversational, natural-language search is now part of your deployment.
Improved precision PII detection for Japanese content
Named Entity Recognition (NER) for Japanese names has been improved, increasing detection accuracy for Japanese personal information across documents. For organizations managing Japanese-language content under privacy regulations, this directly improves the reliability of automated sensitive data classification and governance workflows.
Improved security in the ServiceNow connector
The ServiceNow connector has been updated with security enhancements, improving how OpenText Knowledge Discovery connects to and ingests content from ServiceNow environments. For organizations using ServiceNow as a source repository, this supports more consistent and secure content flows into the AI knowledge discovery pipeline.
To see everything that’s new in 26.2, check out the full release notes.
February 2026: What’s new in OpenText Knowledge Discovery 26.1
OpenText™ Knowledge Discovery 26.1 is easier to deploy, easier to use, and easier to scale. This release introduces LLM-powered classification without training data, embeds generative AI question answering directly in Discover, expands global entity recognition, and strengthens connector precision, helping organizations move from search to insight faster.
Deploy OpenText Knowledge Discovery in the cloud
OpenText Knowledge Discovery is now available in OpenTextTM Private Cloud.
Organizations in highly regulated industries can now deploy advanced AI knowledge discovery and knowledge management capabilities, including metadata enrichment, search, and media analysis, within a managed, dedicated cloud environment. This provides the flexibility of cloud with the control, security, and governance that enterprise customers require.
Enrichment updates
AI metadata enrichment now requires less setup and supports broader use cases. Zero-shot classification allows teams to define categories without a costly training phase or difficult-to-find training data. Powered by large language models (LLMs), this capability speeds deployment and reduces dependence on data science resources.
Named Entity Recognition (NER) now includes PII grammars for India, improving detection of addresses and names in regional content. Business grammar extensions also add CV/resume, contract, and invoice entities, expanding OpenText Knowledge Discovery into HR, legal, and finance workflows.
Access your preferred large language model for GenAI chat
The Discover module now includes a built-in chat capability powered by search abstractor. Users can ask questions about their data in natural language and receive clear, summarized answers, without having to scan long lists of results. This helps analysts move from search to insight faster. For organizations using OpenText Knowledge Discovery on-premises, the chat capability supports connecting to the LLM of their choice, giving them flexibility while maintaining governance and control over their data.
Connector updates
Connector enhancements improve how content flows in and out of OpenText Knowledge Discovery. Enhanced filtering gives administrators more control over source ingestion, reducing noise and improving relevance. New field discovery simplifies target repository mapping, making it easier to push enriched metadata back to enterprise systems.
To see everything that’s new in 26.1, check out the full release notes.
October 2025: What’s new in OpenText Knowledge Discovery CE 25.4
OpenText Knowledge Discovery CE 25.4 further enhances capabilities for AI content management, improving connector capabilities, named entity recognition, as well as multimedia recognition, search, and review.
Analyze, enrich, and protect content by collections in OpenText Content Management
OpenText™ Knowledge Discovery now connects out of the box with OpenText™ Content Management collections. Administrators can now mark collections for automated ingestion. This enables enrichment such as generating summaries, transcribing audio and video, redacting sensitive data, and auto-tagging metadata – all without manual setup. The result: faster content preparation, stronger compliance, and better findability.
Filter video clips
The Discover application now gives users the ability to focus on relevant moments with additional clipping and filtering tools, simplifying video review. 
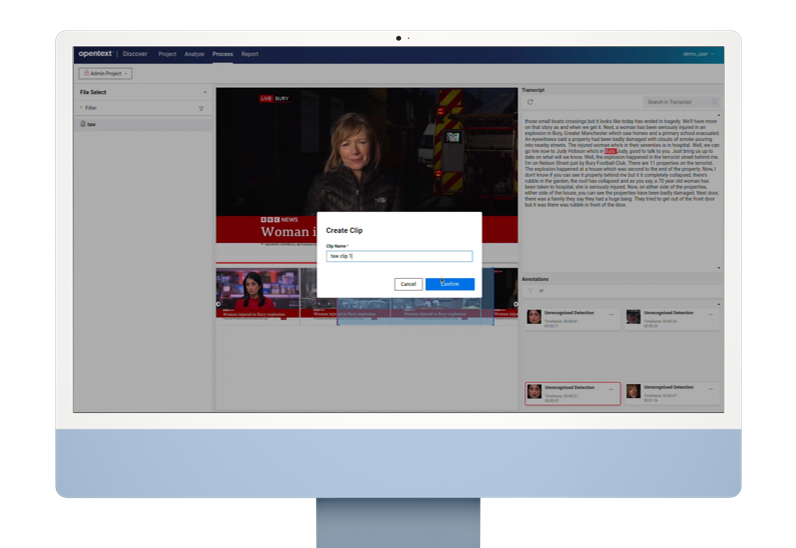
Improvements to content and metadata enrichment
- Speech-to-text now supports multi-channel audio, separating agent and client voices for clearer transcription – ideal for contact center analytics and compliance.
- Named Entity Recognition (NER) adds grammar support for Oman and UAE, improving sensitive data detection and governance for customers managing content from these countries.
Smarter Document processing
- The updated universal redaction flow processes long documents page by page and outputs searchable PDFs. This makes redaction faster, more accurate, and easier to review.
- The enhanced ExecuteDocumentPython processor simplifies customization. Developers can now build and modify workflows faster with persistent module support and improved guidance.
Connector updates
The updated Atlassian Confluence connector simplifies deployment and improves security. Customers can now connect to cloud or on-premises Confluence instances without installing plug-ins—reducing maintenance effort and keeping mapped security consistent across environments.
To see everything that’s new in CE 25.4, check out the full release notes.
July 2025: What’s new in OpenText Knowledge Discovery CE 25.3
OpenText™ Knowledge Discovery CE 25.3 enhances AI search, improves performance, reduces compute costs, broadens global coverage, and helps investigators connect insights across complex data.
Aviator Search is fully integrated into OpenText Knowledge Discovery
Aviator Search is now built into OpenText™ Knowledge Discovery. Users can perform GenAI-driven, natural-language searches across multiple content repositories from a single, integrated platform.
Performance and efficiency improvements
Speech-to-text and facial recognition are now faster and more efficient, reducing overall compute and power consumption.
Added OCR language
OCR now supports the Hong Kong Supplementary Character Set, expanding language support.
Connection & LLM integrations
The Discover application embedded video player adds preprocessing for review and snapshot generation, helping investigators capture relevant frames and move from visual evidence to analysis faster.
To see everything that’s new in CE 25.3, check out the full release notes.
May 2025: What’s new in OpenText Knowledge Discovery CE 25.2
This OpenText Knowledge Discovery (IDOL) CE 25.2 release includes various functional and performance improvements, new connectors, file format support, and many other additions.
New connectors
- Improved OpenText Information Archive connector – An updated bidirectional connector for the Information Archive repository allows it to archive data as well as search and understand previously archived data.
- New Guidewire connector – A searching connector enables the ingestion of contract and policy content into the OpenText Knowledge Discovery index.
Named Entity Recognition – Landmarks exposed to pre-process
- Defined improvements in Named Entity Recognition – Added elements for Turkish Address, more city names in NZ Addressand the NZ Social Welfare number.
- Defined improvements in PCI – Added extra delimiters for card details, in names and medical details, as well as expanded landmarks for Telephone context matching.
- PII Japanese names accuracy improved – Increased accuracy of Named Entity Recognition detecting Japanese names, and improved ability to correctly identify Japanese names within a document.
Opentext File Content Extraction updates and other improvements
- File formats – New Design Web Format (DWF) filter support, metadata now available from password-protected iWork files and additional formats detected.
- Performance improvements – A reduction in the iWork reader disk footprint as well as a reduction of the footprint of the common third-party libraries.
- Easier access to HTML Export from Filter – Improved ability to select XMP metadata elements and subfile extraction arguments added to C++ API
- OEM platform – OEM Easier fault diagnosis with library-wide logging, improved security of inter-process mechanisms and better HTML Export fidelity for DWG Docs.
January 2025: What’s new in OpenText Knowledge Discovery CE 25.1
Organizations are looking to access all their Enterprise Data; but in a world where 90% of existing corporate knowledge is in Unstructured formats, over 50% of organizations are not tapping into this aspect of their knowledge with any form of discovery. Customers can use OpenText Knowledge Discovery with new interfaces, including using Natural language questioning to reach their information securely across all users.
This OpenText Knowledge Discovery (IDOL) CE 25.1 release includes various functional and performance improvements, new connectors, file format support, and many other additions.
New APIs added
PII named entity resolution REST API – created a published REST API to access OpenTex Named Entity Recognition for PII functionality. Simplifies the adoption of Knowledge Discovery Al technology by internal and external OEMs
Rich-Media analysis REST API – created a published REST API to access all Rich Media analytics functionality. Simplifies the adoption of Knowledge Discovery Al technology by internal and external OEMs
Ingest and connectors
New OpenText DAM connector
- A highly functional connector to the OpenText DAM product. This allows OpenText Knowledge Discovery to ingest and enrich content from the DAM repository and keep the data synchronized between the two systems to provide DAM content filtering using the Search Abstractor API
Improved security in OpenText Content Management (Extended ECM) Connector
- Increased alignment of document security policies between OpenText Content Management and OpenText Knowledge Discovery
- OpenText Content Management has numerous document security models above and beyond document folder based, where possible these have now been mapped to OpenText Knowledge Discovery’s understanding of access rights
OpenText Named Entity Recognition – Landmarks exposed to pre-process
Defined grammar landmarks are now visible at the pre-process stage of OpenText Named Entity Recognition
- Pre-processing can significantly help in reducing latency and workload, landmarks can be used to help make selection decisions at this early stage. DLP OEM vendors will benefit from this.
PII Thailand names accuracy improved
- Increased accuracy of OpenText Named Entity Recognition detecting Thai names – the new grammar has an improved ability to correctly identify Thai names within a document
Deployment and other improvements
Automatic scaling OpenText Knowledge Discovery platform for Kubernetes
- Published Helm charts to deploy OpenText Knowledge Discovery with the ability to automatically scale resource – deployment size flexibility along with simplified expansion as and when required
Vault integration with OpenText Knowledge Discovery components
- OpenText Knowledge Discovery microservices can securely store passwords and keys in the Vault repository (or equivalent)
- Customers will benefit from cloud deployment best practice of secure central storage of passwords and keys etc.
December 2024: What’s new in OpenText Knowledge Discovery CE 24.4
Organizations are looking to access all their enterprise data; but in a world where 90% of existing corporate knowledge is in unstructured formats, over 50% of organizations are not tapping into this aspect of their knowledge with any form of discovery. Customers can use Knowledge Discovery with new interfaces, including using natural language questioning to reach their information securely across all users.
This OpenText Knowledge Discovery (IDOL) 24.4 release includes various functional and performance improvements, new connectors, file format support, and many other additions.
New API added
Search Abstractor Rest API – created to support conversational question and answering with better context for AI generated responses. Conversation server, working with FAQ answers through Answer bank, Fact bank and now LLM’s remembers the context of questions within the conversations service in Knowledge Discovery. Adding to the great governance provided by curated answers.
Filtering support in the Search Abstractor adds parametric fields for pre-filtering of documents. The search results can provide microscopic view of either single or multiple documents through criteria for fine grain filtering. The searching can now utilise prior knowledge to allow focus on RAG document retrieval, by using parametric fields to build a subset of entities for RAG.
Working across text documents and images simultaneously in the search abstractor. Searching can now take criteria of both text and images as search criteria, and the results will also include similar images making Multi Modal search available.
Ingest & connectors
- Salesforce – Updating the connector to stay up to date with the changes in Salesforce.
- Additional Pre filtering for focused selection added to OpenText Core Content Management & OpenText Content Management.
- IBM FileNet P8 Each document in FileNet can have multiple binary files which we now interrogate.
Text analytics
- Analytics: LLM based image matching – Image based transformers can be used to generate vectors for the Knowledge Discovery (IDOL) Index. Customers can now search for similar images based on not just the textual description but also the actual image content.
Media Server
- The Media Server as a NiFi Processor is now available with full functionality. This allow NiFi workflows and the ability to scale and manage the Media Server app though Nifi clustering.
- Demo application with abilities to process and analyze images and other functionalities is now available in the Media Server for ease of use.
File content extraction
- Filtering of Source Code comments
- Support added for Metadata output for .mht files & QuickTime (.mov) files.
- Extended format detection, with support for 93 additional file formats.
- In HTML Export the pdf2sr reader to extract images from pages in a PDF file, you can now configure the size of the images to produce.
Deployment & other improvements
- HELM charts for Kubernetes provide a comprehensive set of options to assist complex deployments. With the 24.4 release we bring further enhancements to our HELM charts.
- Named Entity Recognition SDK: You can load multiple grammars and then dynamically turn off what it is not needed for a particular document, allowing the flexibility of swapping grammars with less degradation of performance in comparison to the loading unloading cycle of grammars. The new thing is a reducing of the overall impact of this process.
July 2024: What’s new in OpenText Knowledge Discovery (IDOL) CE 24.3
OpenText Knowledge Discovery CE 24.3 is a significant release for the third quarter of CY24. There is an increasing need for companies to reach a greater variety of data, which adds to the complexity of their search types. We allow all customers to achieve a suitable response in their enterprise-wide search across all levels of an organization.
Now part of Content Services, the combination of best of breed products will help organizations who are looking to access all their corporate knowledge through enterprise search. Bringing additional abilities to derive deeper insights, reach actionable conclusions quicker, and gaining a new level of investigative analytics, across content, teams, and projects. Document level security is also enhanced, with extra features to report and export securely and track data delivery end to end.
The Knowledge Discovery CE 24.3 release includes various functional and performance improvements, new connectors, file format support, and many other additions.
The main improvements in version CE 24.3 are listed below:
Ingest
- Microsoft Teams, Zoom, Cisco Webex and Google Chat connectors – New connectors allow customers to collect collaborative video meetings for retrospective analysis and/or content retrieval as part of aviator search.
Text Analytics
- Search abstractor – Customers will have better context provided by the RAG to pass on to the GenAI, therefore experiencing a higher likelihood of a correct answer being produced.
- Specific document retrieval – Customer can ask the system to find and return a specific document that matches their unique specification.
Rich Media Analytics
- OCR improvement – Improved OCR for better support of scrolling text. Customers will experience a higher accuracy of extracted text from video imagery.
- Speaker ID improvement – Customers will experience a higher accuracy of Speaker ID from video or audio files.
KeyView
- Added Audio and Video to the Export SDK.
- Added 30 new formats to File detection.
- Metadata API Improved to limit duplicated data.
- New .NET API.
- Added support for Python 3.12.
Solutions
- Knowledge Discovery Discover – Discover provides investigative analytics and advanced UI for searching and analyzing relations between objects, with project and team collaboration along with full oversight on the analytics process.
- Knowledge Discovery for Microsoft Exchange – Knowledge Discovery can be added as a BOT in MS Exchange allowing customers to directly access the functionality via simple natural language prompts emailed to a BOT email address in MS Exchange.
Deployment & Licensing changes
All components are now published to the Public Docker Hub repository to allow easier installation, maintenance and upgrades.
- Eduction Python EDK – Customers who prefer to program using the popular Python language can now use it to control our Eduction engine, simplifying their integration experience.
- Eduction for Windows ARM – OEM users of Eduction EDK can now deploy on Windows ARM systems.
- Additional license feature
- From CE 23.2, we are introducing an additional license feature – a “version.key”
- The file is available in the SLD portal for customers with an active support contract and is required for all Knowledge Discovery installations running CE 23.2.
- New key will be issued with every future Knowledge Discovery release.
April 2024: What’s new in OpenText Knowledge Discovery (IDOL) CE 24.2
Organizations are looking for conversational access to enterprise data; in a world where 90% of existing corporate knowledge is in unstructured data, over 50% of organizations are not tapping into this aspect of their knowledge with any form of discovery. Customers can use the new interfaces with Q&A using natural language questioning to deliver their information with data securely to all users.
This OpenText IDOL 24.2 release includes various functional and performance improvements, new connectors, file format support, and many other additions.
New solution added: Teams client
- Customers can access functionality using simple natural language prompts directly via the Teams interface.
Ingest & connectors
- Drupal Connector – Updated to support the latest API changes and allow data extraction from old and new Drupal versions.
- Google Workspace Connectors – Content extraction is now accessible from the major Google Workspace apps including Mail, Calendar and Chat using dedicated connectors.
- Web Connector 2FA – Updated to allow 2Factor Authentication.
- IDOL Media Server – Can now run within NiFi, allowing processing of media streams & sources.
Text analytics
- Analytics: Search abstraction – IDOL can now automatically decide which index type to use to achieve the best response. The functionality abstracts the complexity of search types, democratizing Enterprise search, and allowing all users to achieve a suitable response, across all levels of an organization.
- Multi-document summarization – Generative summary compiled from answers sourced from multi documents. The functionality provides richer answer to any question asked as it can be the combination of multiple parts sourced from different documents.
- Dynamic clustering of vector results to identify grouping – Customers can use the grouping of results to select a variation in documents returned rather than returning very similar documents with no added information.
- Analytics: LLM based image matching – Image based transformers can be used to generate vectors for the IDOL Index. Customers can now search for similar images based on not just the textual description but also the actual image content.
Media Server
- The Media Server as a NiFi processor is now available with full functionality. This allow for NiFi workflows and the ability to scale and manage the Media Server app though Kubernetes.
- Demo application with abilities to process and analyze images and other functionalities is now available in the Media Server for ease of use.
KeyView
- Tabular data detection for One Note & pipe separated text.
- OCR is now available on MacOS through the KeyView SDKs.
- Header & Footer are now configurable through Python APIs.
- Significant Performance improvements through Shared Memory Streaming.
- Additional Formats, Security & Compatibility improvements.
Deployment & other improvements
- HELM charts for Kubernetes provide a comprehensive set of options to assist complex deployments. CE 24.2 brings further enhancements to our HELM charts.
- Eduction SDK Post-processing access to match context.


