What’s new in OpenText eDiscovery
The latest updates include ....

OpenText™ eDiscovery (Axcelerate) is a flexible, powerful, end-to-end eDiscovery and investigations platform that helps legal teams get to facts that matter sooner and inform case strategy.
OpenText eDiscovery 26.2: Expanded capabilities across eDiscovery Aviator, Chronology, review, redaction, and ingestion
OpenText eDiscovery 26.2 delivers an enhancement to previous Aviator Rapid Exploration capabilities, deeper chronology tooling, broader language support, Excel redaction enhancement, and ingestion performance improvements.
Aviator Rapid Exploration enhancements (Cloud only)
Building on the Rapid Exploration capability introduced in 25.4, this release adds visibility into the search criteria used in a prior exploration before launching a new one. Rapid Exploration is now available within the OpenText Investigation module, extending its issue-driven document discovery to investigation workflows.
Chronology enhancements
Several additions deepen Chronology’s usefulness for matter preparation and deposition readiness:
- Use eDiscovery Aviator (Cloud only) to generate an in-context event-level summary using all available event information, with the ability to remove a generated summary from event view
- Centralized configuration management page for Chronology
- Deposition management readiness, including Audio/Video files and Excel support for the spotlight viewer so that you can mark specific portions of a video or Excel file
- Add documents to an event directly from the Chronology page using document IDs or via bulk CSV load
Amazon Translate — multi-language document support (Cloud only)
Documents containing multiple languages can now be processed using Amazon Translate, increasing the efficiency of language translations in matters involving multilingual documents.
Optimized dataflow
26.2 brings several infrastructure-level updates to improve performance and data connectivity:
- Distributed indexing delivers 3-4x faster ingestion speeds
- MS Purview integration enhancements for improved connectivity with Microsoft’s compliance ecosystem
- MS Purview parser enhancements for more accurate and complete data processing from Purview sources
- Parser enhancement to ensure that all content and nodes of XML files are captured
- Google Vault exports parser enhances the processing of email and Google Drive data exported with Google Vault.
Aviator Flex feature (Beta launch 26.2), (Cloud only)
This new feature allows users to run any custom AI prompt against any set of documents in the collection and save the results directly to a custom text field in the database. Unlike previously released predefined Aviator features, Aviator Flex gives legal teams the freedom to ask exactly what a matter demands — and makes those AI-generated insights persistent, searchable, and available across the entire team for review, reporting, and trial preparation.
OpenText eDiscoveryCE 25.4: Introducing Aviator Rapid Exploration and enhanced review and chronology capabilities
OpenText is pleased to announce a powerful set of enhancements to OpenText™ eDiscovery cloud deployments, designed to accelerate legal workflows, improve review accuracy, and enhance collaboration.
This release introduces Aviator Rapid Exploration, a new Gen-AI-powered capability that transforms how legal teams uncover key documents, prioritizing issue-driven exploration over traditional document review. Alongside this innovation, we’ve added precision and recall quality metrics to OpenText™ eDiscovery Aviator Review, and enhanced OpenText eDiscovery Chronology with audit reporting capabilities. Together, these updates empower teams to work smarter, faster, and with greater confidence – whether you are investigating your data and evaluating your case, completing a review for production, or mapping the evidence against a timeline to understand the sequence of events and reveal patterns and insights.
- Introducing OpenText eDiscovery Aviator Rapid Exploration (Cloud only)
A new way to uncover the key documents relating to issues in your case before committing to a full document review. Aviator Rapid Exploration fundamentally changes the “review before you know” dynamic by flipping the traditional sequence. Instead of reviewing documents to find issues, legal teams can now explore specific issues to find the most relevant documents and insights. Using Gen-AI technology combined with predictive algorithms, Rapid Exploration immediately dives deep into specific areas of concern, generating a comprehensive report that organizes critical documents by train of inquiry and provides the strategic intelligence needed for informed decision-making. This isn’t surface-level keyword searching—it’s sophisticated analysis that delivers information in the context of relationships and legal concepts.
- Precision and recall quality metrics added to Aviator Review (Cloud only)
When the “Compare with human review” toggle is activated in the Aviator Review panel, users can view precision and recall quality metrics that compare Aviator Review findings against human tagging. This feature provides valuable insight into the accuracy and effectiveness of AI-assisted document review.
- Expanded audit reporting in Chronology (Cloud only)
User and topic audit reports have been added to Chronology, providing detailed visibility into who performed which actions and when. These reports enhance traceability and support seamless collaboration across teams by allowing team members to track decisions, monitor document handling, and view when topics are added or removed from events in the Chronology timeline. With search and Smart Filter support, users can more easily search and filter Chronology items to zero in on key events and documents.
OpenText eDiscovery CE 25.2: Introducing eDiscovery Chronology for enhanced evidence organization
We’re excited to announce the latest update in OpenText eDiscovery CE 25.2, introducing a powerful new tool that transforms how legal teams organize and analyze evidence. Here’s what’s new:
OpenText eDiscovery Chronology
In modern litigation and investigations, organizing massive volumes of digital evidence chronologically to understand the who, what, where, and when of a matter can be daunting, labor-intensive, expensive, and potentially risky. The new OpenText™ eDiscovery Chronology addresses this challenge head-on.
This interactive chronological narrative building tool helps legal teams track, organize, and analyze evidence by date—with full control of event metadata and complete audit trail capabilities. With Chronology, legal teams can leverage technology to streamline an otherwise manual task and quickly gain a clearer understanding of the sequence of events that may make or break a case.
With integrated visual Chronology, legal teams can:
- Easily identify potential gaps or inconsistencies in evidence earlier, reducing risks and unpleasant surprises
- Save time by organizing events and facts without having to copy and paste text and link documents in Excel, Word, or third-party software
- Quickly zero in on specific events or facts at any time, for faster, easier, and more thorough client reporting, early case assessment, and preparation for depositions, hearings, settlement discussions, and trial
Chronology is a key feature that has been frequently requested by our customers and represents a significant enhancement to our platform’s capabilities.
In addition to the new Chronology feature, OpenText continues to release enhancements to our existing capabilities.
OpenText eDiscovery Aviator Key Document Summary – Now exportable!
Initially released in April 2024, Aviator Key Document Summary empowers legal teams to create an AI-generated summary of key documents, complete with links to the documents, for improved document review efficiency and rapid insight into the case. Now with CE 25.2, legal teams can more easily share document summaries with team members and clients with the ability to export Key Document Summaries, complete with working document links.
Aviator Review – More intuitive than ever
In our ongoing effort to increase efficiency and automate first-pass review, we have simplified the OpenText eDiscovery Aviator Review process to two simple steps:
- Input your review criteria
- Identify the designated document set on which you want Aviator Review to run
It is really that easy, and after the Aviator results are returned, legal teams have the option to quickly QC the document set using the “compare with human review toggle” and selecting the coded review field to be used for comparison.
Expanded bulk redaction capabilities
Accurate and consistent redaction of privileged, confidential, or sensitive information across all document formats is a critical component for reducing production risks. Inadvertent production of privileged or sensitive information is a legal team’s worst nightmare. As the type of data involved in litigation and investigations continues to become more diverse—going far beyond email and Word documents—it’s essential that bulk redaction tools keep pace. That’s why we’re pleased to expand OpenText eDiscovery bulk redaction to support the chat-specific redaction view. We have also added support for Social Security Number patterns in the Bulk Redaction wizard for the native Excel viewer, the audio/video viewer (Cloud only), and the HTML chat viewer.
Additional new redaction capabilities include:
- New “change redaction” functionality for the near native Excel viewer, the audio/video viewer (Cloud only), and the HTML chat viewer
- The ability to centrally manage the addition and deletion of redaction reasons from within the Review & Analysis module
- The addition of a dedicated Regular Expressions (RegEx) tester to support users writing their own customized RegEx for bulk redaction
- An improved RegEx pattern search for birthdates
These updates in OpenText eDiscovery CE 25.2 represent our ongoing commitment to providing powerful, user-friendly tools for modern eDiscovery workflows. By introducing new functionality and enhancing existing key features, we’re responding to our most frequent customer requests and helping legal teams work more efficiently and effectively than ever before, delivering better outcomes for their clients and organizations.
OpenText™ eDiscovery CE 25.1: Expanding capabilities and streamlining workflows
We’re excited to announce the latest updates in OpenText eDiscovery CE 25.1, delivering enhanced GenAI functionality, improved redaction tools, and new data integration features. Here’s what’s new:
Transparent GenAI decision-making
Understanding OpenText eDiscovery Aviator Review document categorization just got easier with the new “Aviator Review last reasoning” field. Users can now view the LLM’s reasoning directly in the results list alongside the “Aviator Review Results” column. This transparency enhancement enables better oversight of the review process, and the reasoning data can be exported for further analysis or documentation purposes.
Enhanced OpenText eDiscovery Aviator GenAI functionality
Our OpenText eDiscovery Aviator functionality, including Aviator Review, Aviator Summarization and Key Document Summary, has been upgraded to handle larger documents with greater efficiency. At CE 25.1 enhanced chunking technology enables support for documents exceeding 180,000 tokens (approximately 60 pages) allowing legal teams to analyze and summarize lengthy documents without limitations.
Advanced redaction capabilities
We’ve reimagined our automated redaction functionality to provide an even more intuitive experience. The global redaction wizard has been rebuilt with user-friendly improvements.
For Cloud customers we’ve also extended support to the near native Excel viewer as well as the audio/video viewer and added the ability to hide redacted rows, columns, and sheets in Excel files during production, offering greater control over sensitive data management.
Enhanced audio/video timeline analysis (cloud only)
The media viewer now offers sophisticated speaker segmentation capabilities for audio and video files processed after the 25.1 release. Users can view audio streams separated by individual speakers in the timeline view, along with the ability to filter transcripts by specific speakers. This enhanced functionality makes it easier than ever to navigate and analyze audio/video content, particularly in cases involving multiple participants or lengthy recordings.
LaunchPad self-service Microsoft Exchange Online (M365) cloud connector (cloud only)
Streamlining data collection processes, CE 25.1 introduces direct self-service crawling capabilities for M365 data to Cloud applications. This new feature eliminates the time and hassle of extraneous data export and loading enabling legal teams to access critical cloud data with unprecedented ease and flexibility. To ensure M365 data remains secure this new feature incorporates secure authentication management through the new LaunchPad Source Systems page and integrates with AWS Secret Manager for secure credential storage.
These updates in OpenText eDiscovery CE 25.1 represent our ongoing commitment to providing powerful, user-friendly tools for modern eDiscovery workflows. By expanding AI capabilities, enhancing redaction tools, and streamlining data integration, we’re helping legal teams work more efficiently and effectively than ever before.
December 2024 (24.4) What is new in OpenText eDiscovery (Axcelerate) 24.4
We’re thrilled to announce the latest updates in OpenText eDiscovery CE 24.4, designed to enhance your e-discovery workflows with powerful new features and improvements. Here’s a closer look at what’s new:
New OpenText eDiscovery Aviator Summarization (cloud only)
Introducing OpenText eDiscovery Aviator Summarization. Powered by generative AI (GenAI), this document summarization functionality leverages deep learning to interpret and synthesize information from lengthy documents, providing concise summaries that help users quickly grasp context and implied meanings. With GenAI summarization, you’ll uncover deeper insights faster than ever before.
Improved OpenText eDiscovery Aviator Key Document Summary (cloud only)
With the latest enhancement to Key Document Summary, users can access the documents referenced in the AI-generated consolidated summary using a new link that displays at the bottom of the Key Document Summary panel.
Near Native Excel Viewer (cloud only)
We’re making it easier than ever to handle Excel documents with the Near Native Excel Viewer. Users can now produce redacted Excel files in both PDF and image formats, providing greater flexibility and convenience when working with sensitive data.
Enhanced audio/video (AV) transcriptions (cloud only)
See who is speaking! With CE 24.4, new AV transcriptions automatically include generic speaker identification to make transcript review easier and faster. Other key AV transcription enhancements include the ability to filter the redaction list by redaction reason and redaction type.
Custodian Merge (cloud only)
The new Custodian Merge functionality in LaunchPad allows users to quickly remedy errors or inconsistencies in custodian names or profiles made during data loading. This feature simplifies the process, ensuring that your custodial data is always accurate and up to date.
PDF document splitting
Managing large PDF documents just got easier! Users can now select a subset of pages from a single PDF file to create sub-documents. This feature comes with tracking capabilities and the ability to delete sub-documents, giving you greater control over your data.
These updates in OpenText eDiscovery CE 24.4 are designed to enhance productivity and streamline your legal workflows. We’re committed to continuously improving our platform to meet your needs. Explore these new features today and experience the future of e-discovery!
July 2024 (24.3): What is new in OpenText Axcelerate 24.3
Enhancing the power of Axcelerate with Aviator for GenAI Review
With Cloud 24.3 OpenText provides Axcelerate Cloud users with the opportunity to revolutionize their review process with Aviator GenAI review.
eDiscovery Aviator Review functionality
Harnessing the power of large language models (LLMs), Aviator Review analyzes and categorizes large volumes of documents as responsive or non-responsive based on the input of plain language review criteria to help reduce the time and cost associated with traditional first-pass responsiveness review. Using the intuitive review criteria window, users can create and refine review instructions without legal prompt engineering expertise.
Aviator Review also helps to control the cost of e-discovery projects by providing users with a cost estimate for each selected data set before they run it. Users can refine review criteria against smaller subsets of data as many times as required and adjust the criteria until it returns optimal results. When users are ready to run the refined review criteria against the entire corpus of the data, Aviator Review provides a comprehensive estimated review cost.
Aviator Review can be used as a standalone tool or in conjunction with the Axcelerate technology-assisted review (TAR) protocols.
Other Axcelerate enhancements at 24.3 include:
Mass edit functionality
For increased efficiency and tracking, Axcelerate now allows Case Managers and Investigators the ability to mass copy, replace, append, prepend, or use search and replace to modify field values.
Enhanced end-to-end audio/video (A/V) workflows Axcelerate helps legal teams manage the complete lifecycle of A/V files. From ingestion, processing, transcription, searching, viewing, redaction and production, Axcelerate A/V workflows help to improve efficiency and reduce costs when manually reviewing and redacting A/V files. New A/V features include:
- Modules are loaded individually to improve the viewer load time.
- Users can jump to specific points in an A/V file by clicking on the corresponding words in the transcript.
- Opus 2 support for redacted A/V files.
LaunchPad
The 24.3 release of LaunchPad offers faster scaling for batch processing in AWS so legal teams can get to review faster.
Improved Excel Viewer*
For CE 24.3 we are migrating to a new near native Microsoft® Excel® viewer service that is centrally hosted in each AWS region. The new service adds these additional Excel features:
- Search within the document from outside of the viewer, with search hit highlighting support.
- Sheet name redaction.
- Ability to edit redactions.
- Improved find and redact.
- Support for Excel in Near Native view in Investigation applications.
April 2024: What’s new in OpenText Axcelerate 24.2
Introducing the extraordinary power of OpenText Aviator for Axcelerate
With Cloud 24.2 OpenText provides Axcelerate Cloud users with the opportunity to leverage Generative AI for case and concept label summarization
Building on a long tradition of incorporating AI and machine learning to speed document review OpenText is thrilled to introduce the next generation of AI-enhanced productivity – Aviator for Axcelerate. Aviator for Axcelerate enables users to create AI-generated summaries of key documents and concept group labels for improved document review efficiency and rapid insight into the case. Leveraging the power of large language models (LLMs) Aviator for Axcelerate creates a summary of key documents, complete with document ID citations to enable users to confirm veracity. Key document summaries help educate review teams for faster and more consistent review and deliver early insight into the evidence to help counsel assess the merits of the case. Aviator will also assist review teams to rapidly understand concept group labels by providing intuitive plain language summaries within the review interface.
Other recent Axcelerate enhancements at 24.2 include:
- Enhanced Audio/Video (A/V) transcript and text redaction options – Search and redaction of A/V files (both video and transcribed text) is easier and more accurate providing users with the ability to:
- View redaction overlays in both the viewer and the transcript prior to production
- Search across timecoded transcript boundaries
- Find portions of the video to be redacted and view results with a corresponding time stamp
- Support archive and restore for projects in which the A/V viewer is activated
- LaunchPad enhancements – Self-service data upload and processing is easier and more powerful with additional status messaging and upload capacity (including PST files)
- Custodian management – Sync custodian data between LaunchPad and Axcelerate for greater visibility and control
January 2024: What’s new in OpenText Axcelerate CE 24.1
Empower your team with more choice to maximize eDiscovery control and efficiency
With 24.1, OpenText now provides Axcelerate Cloud users with more choices than ever to leverage the most appropriate TAR workflow to meet the time, risk, and budget constraints of each project and the preferred workflow of your team.
OpenText eDiscovery solutions have a long history of incorporating artificial intelligence (AI) and advanced analytics to dramatically improve review efficiency and lower costs while ensuring defensibility of process. For more than 15 years we have been the leaders in Technology Assisted Review (TAR) for eDiscovery. While first generation TAR (TAR 1.0) relies on subject matter experts to train the algorithm on a sample data set before review begins, second generation TAR (TAR 2.0) allows the review to commence immediately, saving both time and money. OpenText Axcelerate TAR 2.0, featuring continuous active learning (CAL), learns from all reviewer coding decisions in real time to deliver the most relevant results in the shortest amount of time. Our TAR 2.0 is also paired with a unique contextual diversity algorithm that eliminates the risk of missing relevant documents by surfacing documents from contextually diverse pockets of data. An intuitive TAR interface and workflows reduce learning curves so your team can uncover the most relevant evidence without delay, and visualization tools allow project managers to easily track the progress of review and accurately estimate time to completion.
Whether you choose to leverage the familiar Axcelerate TAR workflow featuring continuous machine learning or try TAR featuring CAL and our unique contextual diversity algorithm, you can be confident that you are maximizing efficiency and accuracy of TAR review for every review scenario.
Other recent Axcelerate enhancements include:
- End-to-end eDiscovery support for audio and video (AV) files – Get the most efficient review of voluminous AV content. OpenText’s built-in browser-agnostic AV viewer features intuitive YouTube like navigation as well as the option to transcribe AV materials for simultaneous review of AV content along with transcribed text. Text transcription of AV content enables you to search, code, redact and produce redacted AV content along with traditional text-based files.
- Side-by-side document comparison – Choose any two documents and Axcelerate will show you all differences between the two documents (even subtle differences) to speed review of near-duplicates as well as conceptually similar documents.
- Self-service data processing – Choose between traditional white-glove data upload and processing to Axcelerate or our new self-service processing and upload where circumstances require immediate review of relatively small volumes of data.
- Password bank – Speed processing time and minimize exception files by adding a list of known passwords for use during processing to attempt to decrypt password-protected Microsoft 365 and Adobe PDF documents.
No matter the circumstances of your case, OpenText Axcelerate offers your team the power to maximize efficiency and minimize risk in every matter.
July 2023: What’s New in OpenText Axcelerate CE 23.2
The latest licensed version of OpenTextTM AxcelerateTM is out! This version includes some great additions, including support for Opus 2TM cloud, document translation for licensed customers of Amazon TranslateTM, decryption during ingestion, undo for bulk tagging, and so much more! Let’s take a closer look.
New Features for Axcelerate Review & Analysis
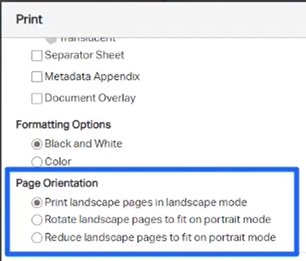
Document Production & Bulk Printing. Both of these features now allow users to select various landscape options.
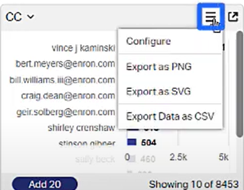
Visualizer. Now includes ability to export any of the charts within Visualizer to an image format and its corresponding data to a CSV format.
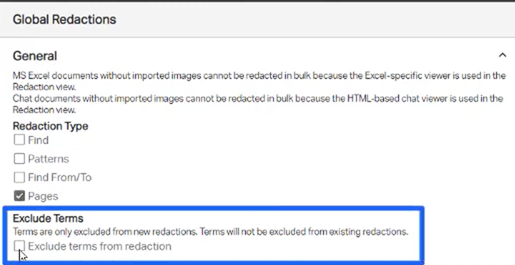
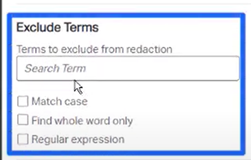
Global Redaction. Now includes an option to exclude terms. Checking the box for Exclude Terms will reveal a new section where exclusionary terms can then be entered.
Redactions. Redaction Reasons and/or redaction associated colors can now be changed across subsets of records. This option can be found under Manage Redactions on the Actions menu within the Analysis page.
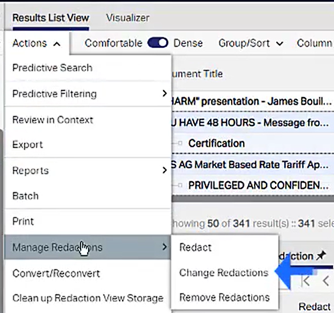
Once Change Redactions option is opened, a pop-up window will appear with the available options for the select records.
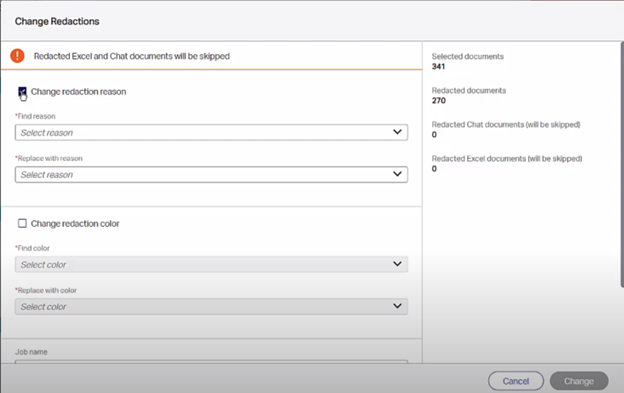
Opus 2. Axcelerate now supports production records being directly ported over to Opus 2 cloud. Once Opus 2 has been configured to connect with Axcelerate, Case Managers can then port production records over within Axcelerate via the Actions menu within the Analysis page.
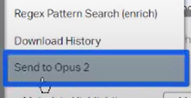
A pop-up window will then appear with options for this job where the Case Manager can select production output and metadata.
Documents sent to Opus 2 can be identified via the Sent to Opus 2 Smart filter under Work Product.
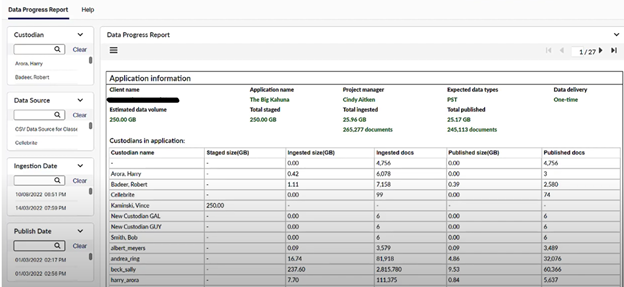
Magellan Business Intelligence. Now includes a Data Progress Report that provides a filterable report on all data sets by custodian with details as to document counts and size.
Business Intelligence also now allows for sharing custom dashboards.
Machine Translation. Axcelerate now has the ability to generate machine translations for customers with Amazon Translate licenses (translations via Veritone is also still available). Once Amazon Translate has been set up, case managers are able to enable it for their projects and select a target langue for translation. Please see your OpenText Program Manager for further details.
RegEx Pattern Search. This feature has now allow users to define pattern searches across the addressee fields as well as the Title field.
New Features for Axcelerate Ingestion/ECA
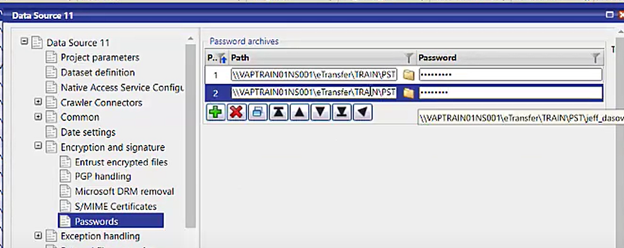
Decryption. 7-zip, office, and PDF files can now be decrypted during ingestion when a list of potential passwords is provided within the Data Source configuration node.
Parsers
Encase Parser. Now supports chat data from MS Teams and Slack.
MS Teams Parser. Now supports the export of Channel names, redactions, edit dates of messages, message deletions, and Urgent and Important flags.
Connectors
MS Teams Connector. Now supports:
- the inclusion/exclusion of all channels of a Team by leaving the channel value empty. A row with a channel name supersedes a row without a channel name; and
- extracting meeting details (start time, end time, duration, initiator).
Outlook for Mac Connector. Now supports 2016 and 2019 Outlook versions.
MS Sharepoint Connector. Now supports indexing metadata of Recycle Bin items.
New Admin Features
OCR. OpenText MindServer AdminTM now allows for changing the language group that will be used by OpenText CaptureTM. This allows for changing character sets used for OCR to accommodate multi-language data sets.
PostgreSQL. Previous version has been upgraded to version 14 with backport available to 22.4.
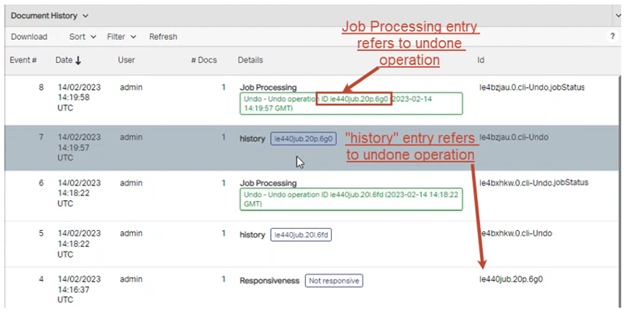
Undo Tagging Operations. Administrators can now use a command-line (undo.bat) to undo bulk or single tag operations. This operation is tracked within both the Jobs Processing Smart Filter and Document History detail.
Performance
Did you know… Axcelerate has made substantial improvements to performance over the last few years? See below for more details:
| Version | Performance Update |
| Axcelerate 20.2 | Index engines improved to handle 50 million records per engine – x5 increase from original limit! Efficiencies to WordMap for improved indexing, record capacity and search retrieval |
| Axcelerate 20.4 | PST Archival handling improved for quicker handling with less exceptions Index Engine Partitions updated to process simultaneously for faster processing and eliminating need for extra Java heap size |
| Axcelerate 21.2 | New memory manager created to protect against OOM query processing Duplicate hash computation moved to index engine Both searches and Search Query Editor reports in Ingestion are run as Jobs and can be sent to generate in the background |
| Axcelerate 22.2 | Distributed worker hosts can be configured on a single engine for improved handling of larger ingestion jobs Further efficiencies to WordMap for improved indexing, record capacity and search retrieval |
| Axcelerate 22.4 | Memory handling improved to prevent OOM issues during near-duplicate detection |
| Axcelerate 23.2 | Near duplicate detection now computes with multi-threading Ingestion performance improved by increasing index threads from 12 to 32 using distributed indexing, enabling redistribution of index across partition via command-line (reindexdocuments.bat) |
October 2022: What’s new in OpenText Axcelerate CE 22.4
In litigation, investigations and regulatory compliance matters, legal teams are under intense pressure to deliver superior results on time and within budget. Staying on top of concurrent matters requires the ability to see the overall status of projects, individual reviewer progress, and the progress of key processes such as overturn tracking and reconciliation. These insights are critical to staff projects effectively, forecast and meet deadline dates, and minimize rework by identifying bottlenecks and catching review discrepancies early.
OpenText Axcelerate 22.4 introduces a new reporting framework based on the Magellan Business Intelligence and Reporting (MBIR) platform. All business intelligence (BI) reports have been transformed in the new platform with additional insights available. Common custom dashboards centered around review productivity will now be available by default in all projects.
CE 22.4 also includes a new user audit logging report so review project managers can monitor review activity by user.
The integration of MBRI eliminates the need for custom configuration of dashboards, enhances usability and provides deeper insights within individual reports with more robust menus. Axcelerate’s new reporting platform is also delivered at no additional costs – clients no longer need to pay for third-party licenses for the legacy reporting features (Qlik).
Additional enhancements with Axcelerate CE 22.4 include:
- A new collector for Slack data to improve collection, ingestion, processing and review efficiency of Slack data for inclusive review;
- The on-premise availability of the advanced chat viewer for chat support (introduced in Axcelerate OnDemand in CE 22.2); and,
- Support for the EnCase EX01 file format to enhance ingesgtion and review all relevant data, whatever the source.
April 2022: What’s new in OpenText Axcelerate CE 22.2
The requirements to collect data inclusively across all sources are more pronounced than ever. The need to include data from smartphones, including chat data is now prominent for litigation and investigations.
Support for the XRY parser
Axcelerate 22.2 introduces support for the XRY parser as an additional tool for collecting smartphone data for use by legal teams to support litigation and investigations and for use by policing and investigative agencies conducting criminal or regulatory inquiries. Supported data types include SMS, MMS, loose files, chat, geolocation data and browsing data including history and searches.
Enhancements to the Cellebrite parser
The Cellebrite parser, first supported within Axcelerate in July 2021 has also been enhanced to include geo location data, browser data, and notes. Other Cellebrite enhancements include that SMS/MMS exchanged with the same participant are now consolidated in one chat and each voice call is now displayed as a separate document.
Additional features in Axcelerate 22.2 enhance the protection of sensitive data and the ability to audit overturns.
- RegEx pattern editing – Customize existing pre-configured RegEx patterns by editing an existing pattern instead of creating from scratch. This allows custom patterns to be fully supported with their own search filter by replacing an existing pattern that is already embedded in the search filters to streamline the detection and redaction of sensitive data to aid compliance with data privacy laws, improve PII detection for subject rights requests including DSARs and identify affected data in breach response investigations.
- Overturn reporting links to source data – Derive maximum value from overturn reporting by viewing the overturned documents in the results list to see the specific tagging changes. Filter by individual reviewer and key criteria including privilege, responsiveness and issues to see where overturns are occurring to catch issues early and avoid rework later. Instead of just seeing that overturns have occurred, the source data can be easily accessed and audited for enhanced insights.
January 2021: What’s new in OpenText Axcelerate CE 21.4
Greater accuracy in detecting personal data is more important than ever due to cyber security threats, such as data breaches, data privacy mandates and escalating regulatory compliance requirements. To mitigate risk to the organization, swift and accurate identification of personal data is critical. However, many organizations approach it ad hoc, necessitating an efficient approach.
Axcelerate CE 21.4 introduces enhanced RegEx for easier, faster and greater accuracy in PII detection:
- RegEx has been decoupled from the redaction utilities for more direct access within Axcelerate 21.4. The number of pre-configured strings for personal data have been expanded. This makes it faster and easier to discover and redact sensitive data within the review process to avoid passing unredacted personal data to opposing council, to find and isolate personal data involved in data breaches, to redact the data of third parties as part of subject rights requests, and more.
Additional features in Axcelerate CE 21.4 designed to improve review efficiency and drive down the cost of eDiscovery include:
- Overturn reporting to expedite review by helping case managers to catch coding inconsistencies early on to standardize coding decisions and avoid significant rework later.
- Chat attachment previews to address the fact that opening individual documents to assess their content is among the most time-consuming of review tasks. Chat attachment previews allow reviewers to focus their time on attachments that appear to be relevant and avoid time inspecting attachments that are not relevant thereby substantially improving chat data review efficiency.
June 2021: What’s new in OpenText Axcelerate CE 21.2
Legal teams and law firms are under pressure to contain the cost of eDiscovery against rising data volumes and new forms of data such as chat. Axcelerate CE 21.2 provides enhanced control and automation to start review sooner and enhanced chat, data sorting, and batching capabilities to complete review faster.
Update 1: Enhanced control and automation to start review sooner
Driving down the cost of eDiscovery requires a holistic approach to eliminating process lags and maximizing efficiency across all stages of a project. Axcelerate CE 21.2 introduces enhancements to improve control and automation of left-side tasks on the EDRM to get to review sooner:
- Customize project welcome emails to better provide context for reviewers (available for Axcelerate OnDemand and Private Cloud);
- Run searches as jobs to keep working while large searches run in the background; and,
- Automatically decrypt Azure® RMS data via the Microsoft® Information Protection SDK® to quickly expose this data for processing.
Update 2: New tools to complete review faster
Review comprises 70% of total eDiscovery project costs. Every capability that helps speed the review process has a material impact on containing costs. Axcelerate CE 21.2 includes the following features to complete review faster:
- Sort data by word count to better eliminate non-relevant data such as images with alt text; and,
- Group batches by any data field to better align data to the expertise of individual reviewers.
Update 3: Tame unwieldy chat data
Reviewing chat data can take significantly longer than other forms of data because of its volume and structure. Axcelerate CE 21.2 introduces new capabilities to review chat data faster with greater precision:
- Break down chat histories into manageable blocks of time to narrow the volume of data that requires review and make review easier;
- See chat attachments such as links, images and audio/video files to include related data faster; and,
- Connect loose chat files for easier inclusion.
Axcelerate drives down the cost of eDiscovery through analytics and automation. Axcelerate CE 21.2 builds on these capabilities to further help legal teams and law firms to streamline processes before review can begin and to help speed review processes as well.
For more information please visit the OpenText Axcelerate product page, the OpenText Discovery page or the Axcelerate – driving down the cost of eDiscovery video.
March 2021: What’s new in OpenText Axcelerate CE 21.1
Update 1: Axcelerate Investigation drives faster and richer ECA – now available OnDemand
The Axcelerate Investigation platform–first released in October 2020 and part of the integrated OpenText™ Axcelerate™ investigation and eDiscovery solution–goes beyond traditional ECA tools to assist teams to find the facts quickly for active or anticipated litigation and investigations. Axcelerate Investigation combines robust collection, processing and culling with powerful front-loaded analytics in a single solution. Legal teams gain early insight into their data leveraging advanced analytics, minimize resources and costs, and maximize efficiency. A single platform, Axcelerate Investigation reduces potentially error-prone data transfers common with multiple point solutions and also reduces–or eliminates altogether–time-consuming and costly downstream document review costs. When full review and production of data is warranted, all data and work product can be automatically uploaded directly from Axcelerate Investigation to Axcelerate Review & Analysis OnDemand.
Update 2: Axcelerate Visualizer Heat Maps introduce multi-factor visual analytics
Axcelerate Visualizer, first introduced in October 2020, brings data analytics into focus for rapid insight into matters of all sizes and complexity. Axcelerate Visualizer Heat Maps expand on these capabilities by introducing flexible visual associations amongst analytics tools for greater visibility into the relationships, patterns and anomalies within the data.
Axcelerate Visualizer Heat Maps expand on these capabilities by introducing flexible visual associations amongst analytics tools for greater visibility into the relationships, patterns and anomalies within the data. Visualizer Heat Maps present new opportunities for insights that were previously impossible, or highly manual and time-consuming to derive. For example, reviewers can see file types overlaid with MIME types, or file sizes etc. for a multi-dimensional understanding of data or fact versus opinion ratings can be superimposed by custodian to better understand which custodians are prone to unsubstantiated assertions, and more.
Update 3: Near native Excel, additional efficiency enhancements and expanded connectors
Axcelerate CE 21.1 also introduces the integrated conversion of Excel files to expedite and simplify the review and redaction of this often-critical file type. Axcelerate CE 21.1 adds extensive and flexible redaction capabilities to help assure that privileged, personal or other sensitive data within Excel files can be effectively remediated with greater ease and assurance.
Other review efficiency enhancements in Axcelerate CE 21.1 include new tools for reviewing data in context so reviewers can choose how they want data to be ordered (e.g. by Bates number), and enhancements to the review progress and reviewer productivity reports so project leads can better deliver projects on time and within budget. Axcelerate’s extensive data source connectors have been expanded further with CE 21.1 – new connectors for WebDAV™ / Druva™, Google™ Calendar™, Google™ Cloud Storage™ and AWS™ S3™ have been added.
November 2020: What’s new in OpenText Axcelerate CE 20.4
Update 1: Axcelerate Investigation drives faster and more comprehensive early case analysis
With an increase in regulations, ESI types and data volumes, and data privacy mandates, efficiently assessing data and finding the information that will tell the story quickly yet comprehensively is critical to making decisions early on to manage costs and risk.
The all-new Axcelerate Investigation platform, part of the integrated OpenText™ Axcelerate™ investigation and eDiscovery solution, goes beyond traditional ECA tools to find the facts quickly for active or anticipated litigation. Axcelerate Investigation drives effective early case assessment and analysis by combining data collection, processing and culling capabilities with front-ended analytics to swiftly find facts and patterns for rapid insight and decision-making. These include stackable metadata filters, powerful text analytics and predictive analytics. If a full document review is warranted, data can be transferred seamlessly to the full Axcelerate cloud.
Axcelerate Investigation is also ideally suited to support a broad range of other types of investigations such as compliance, human resources, M&A due diligence, C-suite vetting and more.
Update 2: Axcelerate Visualizer further streamlines workflow
Axcelerate’s new Visualizer dashboard brings data analytics into focus for rapid insight into matters of all sizes and complexity. The new feature allows reviewers to expedite the ability to drill into the analytics faster to find facts and uncover responsive data with greater speed and precision. Axcelerate Visualizer incorporates communications, custodians, file mime types, office flags, phrase analytics, and more.
Axcelerate Visualizer is highly customizable. Reviewers and investigators can choose what data is displayed, how data is presented (e.g. bar graph, pie chart, etc.) and the level of detail for each vantage point into Axcelerate’s analytics. Axcelerate Visualizer is available across the Axcelerate platform including Axcelerate Investigation and Axcelerate Review and Analysis.
Update 3: Axcelerate introduces support for chat
With an increasingly remote workforce, chat has become a prolific part of organizational communications. Axcelerate CE 20.4 introduces the ability to parse data from chat platforms by transposing the data to align to the Axcelerate chat format.
Once ingested into Axcelerate, chat data and related content such as reactions and edits are displayed in a familiar chat style layout for easy review. What’s more is that Axcelerate treats chat like any other potentially critical data. Chat data is integrated into Axcelerate’s smart filters with its own dedicated filter and analyzed in tandem with all other data as part of concept groups, phrase analysis, text analytics and predictive analytics.
Axcelerate CE 20.4 includes a pre-configured parser for Microsoft® Teams® and a generic chat parser for virtually any other chat platform. Additional pre-configured parsers will be rolled out with subsequent releases.
Update 4: Additional reporting, usability, performance and connectors
Axcelerate CE 20.4 also includes new reports to quickly assess reviewer productivity and review progress to improve the ability to manage projects and address bottlenecks. PST extraction has also been enhanced for improved speed and reliability and export templates have been introduced to reduce effort on repeated workflows with similar criteria. New connectors for Gmail™ and Google™ Drive™ are also included to expand Axcelerate’s reach across data sources.
April 2020: What’s new in OpenText Axcelerate Cloud Edition (CE) 20.2
Update 1: New UI simplifies navigation
The new UI provides more than a usable interface. It surfaces contextual insights in a highly visual display that is easy to navigate and allows reviewers to quickly understand the content under review.
Update 2: New entity identification with OpenText Magellan integration
Axcelerate Release 16 EP7 introduced integration with OpenText™ Magellan™ text analytics for sentiment analysis and automated entity identification for people and places. Auto-identification and extraction of entities (organizations) help reviewers answer “who” and “where” questions and home in on relevant content faster.
Enrichment jobs now automatically enhance documents for sentiment and all types of entities with a single operation. In addition to sentiment tonality pie charts, sentiment indicators are automatically ranked within documents so reviewers can zero in on the top positive and negative statements within each document. Statements are also rated as to whether they are based on opinions or facts to help reviewers assess the voracity of interesting comments.
Update 3: Automated document summaries powered by Magellan
Automated document summaries make the efficient review more efficient, eliminating the need to open individual files and review them to figure out what they are about. Individual sentences are assessed within each document and the most representative content is assembled into a concise paragraph for quick insights.
Update 4: “Find more like me” with Predictive Search
Axcelerate’s new Predictive Search provides a “find more like me” capability to easily home in on relevant content. Documents that are known in advance to be highly relevant, or the best exemplars uncovered in initial search results, are compared against the entire corpus to quickly surface documents with similar content. Predictive Search can also be used as a QC tool to quickly assess whether the final discovery set is inclusive of all relevant content.
Update 5: Negative proximity operator
The new negative proximity operator is a powerful tool for isolating homonyms and terms that often appear in signature lines, such as attorney-client privileged, enhancing efficiency and search effectiveness by reducing, or eliminating altogether, false positives, thus minimizing the number of documents that require review. Reviewers can stipulate that keywords have to be within a specified number of words to other keywords to be surfaced as a positive hit, substantially reducing false hits.
Axcelerate CE 20.2 delivers an intuitive UI with simplified navigation and Predictive Search, enhanced entity extraction, document summaries, and a negative proximity operator each of which contribute to review efficiency. Together they deliver a multiplier effect to further elevate Axcelerate as a leading end-to-end eDiscovery solution on a single platform.




