
The way things get named in this industry can be pretty odd. A lot of people have been hearing about how cool a “data lakehouse” is, since it combines the power of a data lake with that of a data warehouse. When I think of a lakehouse, I think of a great place to go fishing and have a few beers. I certainly don’t think about a place to get my analytics done.
That’s one of the reasons why OpenText™ Analytics Database chose to call themselves a “unified analytics platform” instead. In addition, our goal has been to unify different ways of doing analytics, different analyst teams, and different architectures, so “unified analytics” better aligns with our goals. Plus, we feel that the analytics are the point, not where you put your data. Does this mean Vertica won’t function as a data lakehouse? No, it certainly will.
OpenText Analytics Database is a data lakehouse, but we go far beyond the basic requirements of a data lakehouse to do more than the companies that use the term. Let’s start by looking at someone else’s definition of what a data lakehouse is to show that OpenText Analytics Database meets all those criteria.
After each section, look for a “Beyond that” supplement that explains how Vertica builds on the basic foundation. Where is the data lakehouse foundation defined?
There are many on the Internet, but let’s use Databricks’ definition.
Traditional data warehouse
For efficiency, let’s group the capabilities into data warehouse and data lake capabilities, and use their definitions word-for-word.
Transaction support: In an enterprise lakehouse many data pipelines will often be reading and writing data concurrently. Support for ACID transactions ensures consistency as multiple parties concurrently read or write data, typically using SQL.
Schema enforcement and governance: The Lakehouse should have a way to support schema enforcement and evolution, supporting DW schema architectures such as star/snowflake-schemas. The system should be able to reason about data integrity, and it should have robust governance and auditing mechanisms.
Business intelligence (BI) support: Lakehouses enable using BI tools directly on the source data. This reduces staleness and improves recency, reduces latency, and lowers the cost of having to operationalize two copies of the data in both a data lake and a warehouse.
While these may seem like new, cool, cutting-edge capabilities to a vendor with a data lake history, for Vertica, they’re table stakes. Vertica has had full ACID compliance with strong consistency from its beginning. Eventual consistency has always been a dirty word here. If you query Vertica twice on the same data, you WILL get the same answer. Data integrity, governance, and auditing are also ground zero for us, not a reach goal. High-performance business intelligence at virtually unlimited scale has been our bread and butter for years.

Beyond that: Vertica integrates with nearly every BI and data visualization tool on the market. We strive to never limit your analytics.
Traditional Data Lake
Okay, so, what about the capabilities that are traditionally part of a data lake, like:
Storage is decoupled from compute: In practice this means storage and compute use separate clusters, thus these systems are able to scale to many more concurrent users and larger data sizes. Some modern data warehouses also have this property.
Eon Mode, Vertica’s separated compute and storage architecture, became part of Vertica years ago. It has the unique capability to deliver all the advantages of that cloud-native, elastic architecture, regardless of infrastructure, across any cloud, and even on-prem. Vertica Accelerator, our managed service, was recently released as well and is built on this architecture.
Beyond that: When Vertica talks about concurrent users, we mean far more than just ten. Vertica customers often have hundreds, or even thousands, of users accessing the data to drive their job decisions every day.
Support for diverse workloads: including data science, machine learning, and SQL and analytics. Multiple tools might be needed to support all these workloads but they all rely on the same data repository.
As mentioned before, Vertica has always been known for blazing-fast BI. In addition, Vertica not only supports the whole end-to-end data science workflow but also makes it far easier and faster to deploy machine learning models from proof of concept to production than any other platform. And it does so without requiring you to buy a bunch of other tools or an expensive package. All Vertica data science functions are built to work in the database, powered by our engine. They’re built to scale, run in parallel, and run incredibly fast. They all come together as part of the Vertica Unified Analytics Platform. And if you want to add your own, feel free to create an algorithm or function and put it into our UDx framework for near-infinite extensibility.
Beyond that: On top of BI and machine learning, Vertica also supports a lot of other important advanced analytics capabilities like geospatial analytics, event pattern matching, time series analytics, text analytics, … Over 650 functions are built into every version of Vertica, including Vertica Community Edition, the free version, and Vertica Accelerator, the SaaS version.
Support for diverse data types ranging from unstructured to structured data: The lakehouse can be used to store, refine, analyze, and access data types needed for many new data applications, including images, video, audio, semi-structured data, and text.
Data lakes reside on either an object storage system, such as S3, or the Hadoop File System (HDFS). The advantage of these is that you can store a wide variety of things on them, from the highly structured format that Vertica stores its data in, ROS (Read Optimized Storage), to other columnar formats like Parquet and ORC, to semi-structured formats like JSON, Avro, CSV, log files, etc., to completely unstructured data like images and video. Vertica doesn’t analyze unstructured sound, images, or video, but every other kind of data on that list, OpenText Analytics Database can query, train an ML model on, join, etc. Our data sits on object storage right next to everyone else’s, and we analyze it all.

Beyond that: Vertica acts as a query engine, analyzing the data where it sits, rather than requiring an import/translation into our own format before analysis, unlike many other technologies. We don’t ask you to put all your data in our product first, then we’ll analyze it. We work wherever your data currently resides. Vertica even has a handy built-in function called INFER_EXTERNAL_TABLE_DDL, which analyzes a file like Parquet and automatically determines its structure, so you can use that information to analyze the data.
Openness: The storage formats they use are open and standardized, such as Parquet, and they provide an API so a variety of tools and engines, including machine learning and Python/R libraries, can efficiently access the data directly.
Vertica supports SQL and Python as first-class citizen interfaces, with open-source support for many libraries and file types like Parquet, ORC, JSON, Avro, CSV, etc., and, as mentioned before, fast, bidirectional support for Spark. While our internal storage format is proprietary, we also support the open interchange of ML models via PMML, a markup language specifically designed for model sharing. We also import TensorFlow graphs, among others.
Beyond that: Because you can use any of Vertica’s over 650 functions via SQL, R, or Python, you can enable the citizen data scientist who is proficient with SQL and knows your data and use case to use predictive algorithms. Along the same lines, the data science expert who is comfortable in Jupyter and Python never needs to leave that environment to do something simple like look at aggregate sales by region.
End-to-end streaming: Real-time reports are the norm in many enterprises. Support for streaming eliminates the need for separate systems dedicated to serving real-time data applications.
Vertica is both a consumer and a producer of Apache Kafka topics, and many of our customers use similar streaming technologies, such as Amazon Kinesis and Apache Pulsar. Vertica fully supports streaming data with built-in event pattern matching, windowing, moving average, and other IoT and streaming-related capabilities. Vertica customers often have response time requirements in the hundreds of milliseconds, and we meet them every day.
Beyond that: When I mentioned before that we do high concurrency on diverse workloads, that includes constant ingestion and data transformation on incoming streaming data. We can do that, train a machine learning algorithm, power your dashboards, make your applications fly, and still answer any ad hoc queries you might come up with. All at the same time.
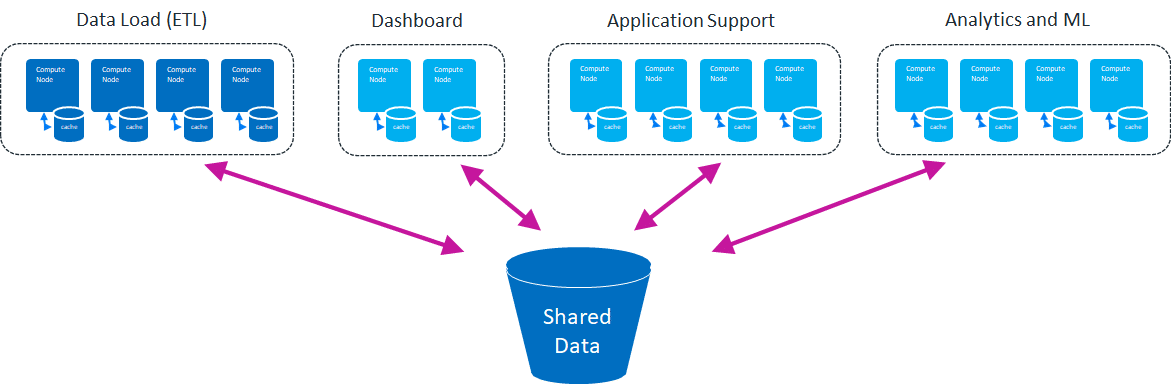
One more thing that isn’t mentioned in the requirements for a data lakehouse, and that Vertica does a bit differently from most other technologies in this space, is its licensing. Dev, test, and high-availability clusters are the same as production with Vertica, because we charge for production only. The rest is included. Our ML and advanced analytics are fast and easy to use because they are included in every version. We aren’t shocked that your company wants to do both BI and data science; that’s a normal part of business these days. Nor are we somehow shocked that you want a development environment as well as test, disaster recovery, and production. For us, these are not extra add-ons or new, cutting-edge improvements; they’re just part of being a good analytics platform.
OpenText Analytics Database lets you go beyond a data lakehouse to truly unified analytics.
And then, maybe we can drink some beer and go fishing after the work is done! 😉


