Many of us on the eDiscovery front line have noticed how much data has changed over the last decade. In the past, it was unusual to get a request to process chat data. And, since COVID, the influx of requests to handle audio/video (“a/v”) files has increased exponentially. In fact, unstructured data is now 80-90% of all new data and it is growing at a rate of three times faster than structured data. By 2025, it is expected to grow to 175 zettabytes—that’s five times the size it was in 2018! [1]
What exactly is unstructured data? The technical definition is any information that is not arranged according to a preset data model or schema. Simply put, if the data is not organized in a manner that makes it easy to process, then it is unstructured. Examples of unstructured data include social media content, chat data, content created with collaborative software, rich media, and machine-generated data.
Challenges
Structured data is generally very easy to process. It has clear and identifiable metadata that can be captured, and its content can be displayed in a standard document viewer. This is not the case with unstructured data. Below are the four main reasons why unstructured data has some obvious challenges within the eDiscovery world:
- Even if the data has an internal structure of some kind, it usually cannot fit into a pre-defined data model. This makes it very difficult to collect, process, and present with the most common eDiscovery software.
- Unstructured data commonly contains billions of items that will require, not only definition but a means to pre-filter and manage in a manner consistent with the needs of the project without trying to boil the ocean.
- Common collaborative elements of unstructured data require special handling to ensure its content, creator/editor, version history, and other tracking information are preserved.
- Unstructured data is commonly updated with new content that may require repeated collections during the discovery process of a project.
By way of a common example of the above challenges, think of that chat thread you have had going for the last three years—a few days or a week may go by with no activity, and then bam! Same players pick up this conversation to provide updates on the same topic or to bring up a new, but similar item. Or perhaps it’s a team chat conversation that covers a wide range of topics. Now, what part of that chat is related to your eDiscovery project? Where is the cut-off point? How much of that thread do you want to view per record in your database? How do you track members of the chat who are added and when, and who are removed and when? All of these challenges require a well-defined game plan. Below, we will review a couple of scenarios that demonstrate how cutting-edge eDiscovery software, such as OpenText eDiscovery, handles these challenges.
Chat Data
OpenText eDiscovery Chat features support chat data from:
- Bloomberg
- Slack
- Microsoft Teams
- Mobile device collections using:
- Cellebrite
- XRY
- Oxygen
- XML formats
Chat data can be ingested into the platform from either an export or directly from the Chat application by using one of the OpenText eDiscovery compatible Connectors (see “Other Structured Data and Connectors” section below). There are no native chat files associated with this type of data – it doesn’t export out like MSG files to an email container. This data is primarily a stream of information that is encoded in a manner that needs to be reassembled for easy viewing (see examples below).
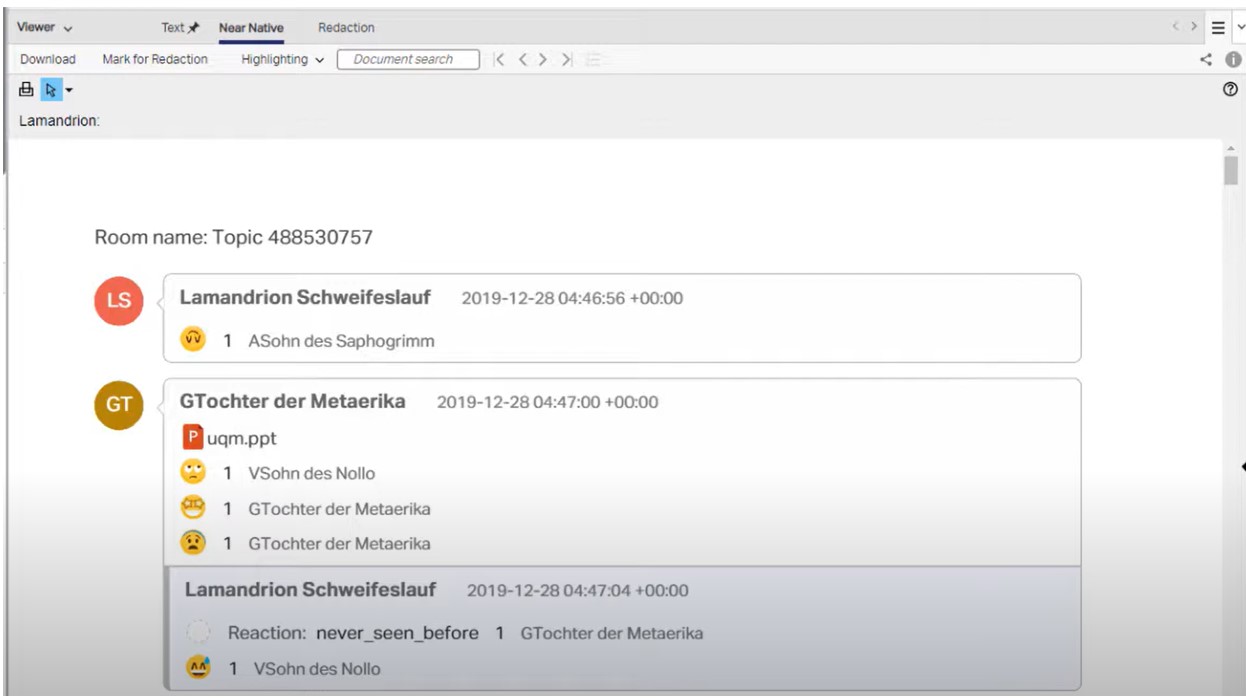
[Example 1: OpenText eDiscovery Near Native view]
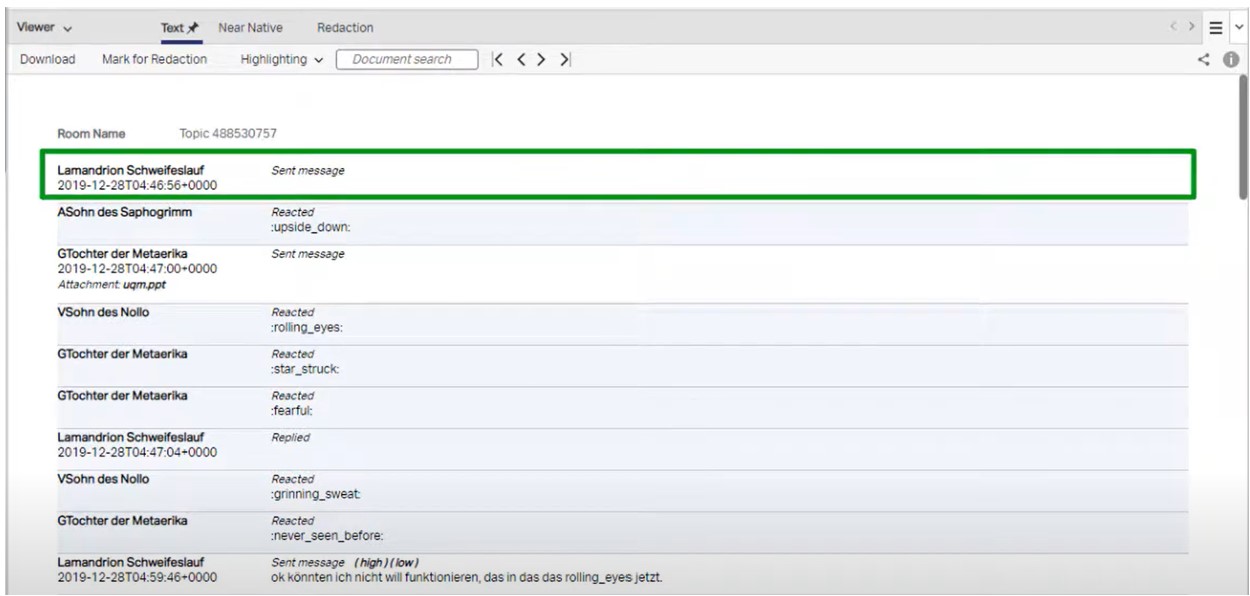
[Example 2: OpenText eDiscovery Text view]
To avoid lengthy chat documents, there are a couple of options that can be applied. The default is to split chats by day. But the system never splits chat messages in channels from their replies, even if they span several days. There is also an option to use Adaptive Chat Splitting that splits chats up by identified gaps within the dates of the conversation thread. Chat splitting can also be disabled, for example, if the case team wants to produce a complete chat as one document.
Regardless of the selected option, locating all chat documents related to the same chat in OpenText eDiscovery is easily accomplished using the Chat History Smart Filter. Other Chat-specific filters include Chat Platform, Chat Event Type, and Chat Count. The Chat Event Type is particularly useful in identifying when new participants are added or removed.
Chat Viewer
The optional eDiscovery Chat Viewer features additional capabilities to facilitate an easier chat review process. This feature includes the ability to highlight select chat contributors using the Members list (see example below).
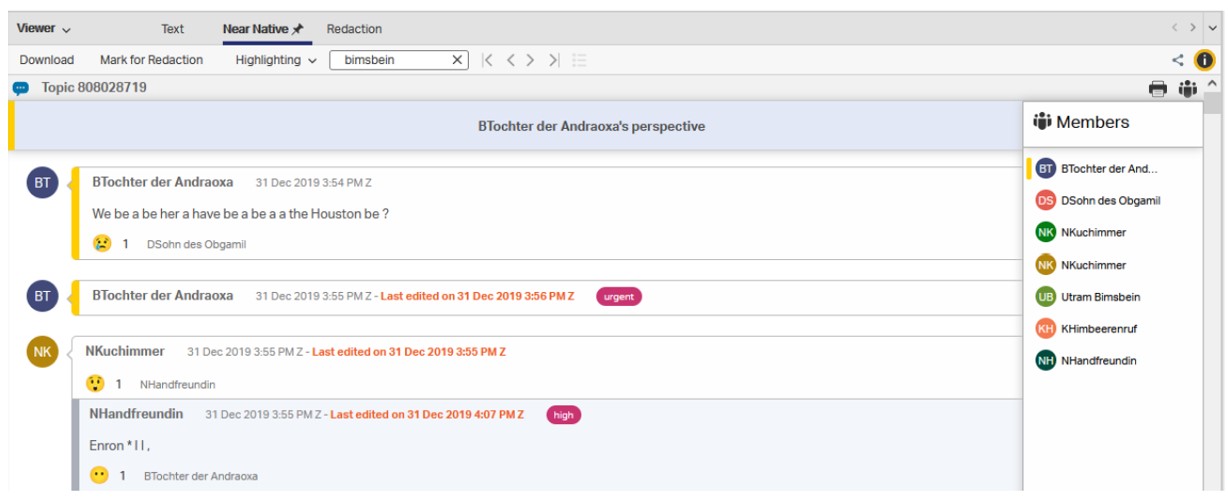
[Example 3: Chat Viewer: Near Native]
While viewing a chat document in the Chat Viewer, users can select specific messages within the chat thread for redaction and production purposes. After selecting the desired messages inside the Chat Viewer, users can then switch to the Redaction view, which will display only those selected messages for that document. Users can then proceed to redact and mark up this view of the document, readying it for production. This simplifies the process of producing only the relevant messages in a chat thread without manually redacting the non-relevant portions. To learn more about OpenText eDiscovery’s chat features, take a look at this short YouTube video.
Audio/Video Support
eDiscovery CE has now rolled out support for audio and video (“A/V”) files in its 23.4 release. As A/V files are not inherently searchable, a new Transcription feature is now available to quickly generate text from your media. This release also includes an Audio-Video Player to allow for easy playback. Users can even synchronize the playback with the media’s transcript (see example below).
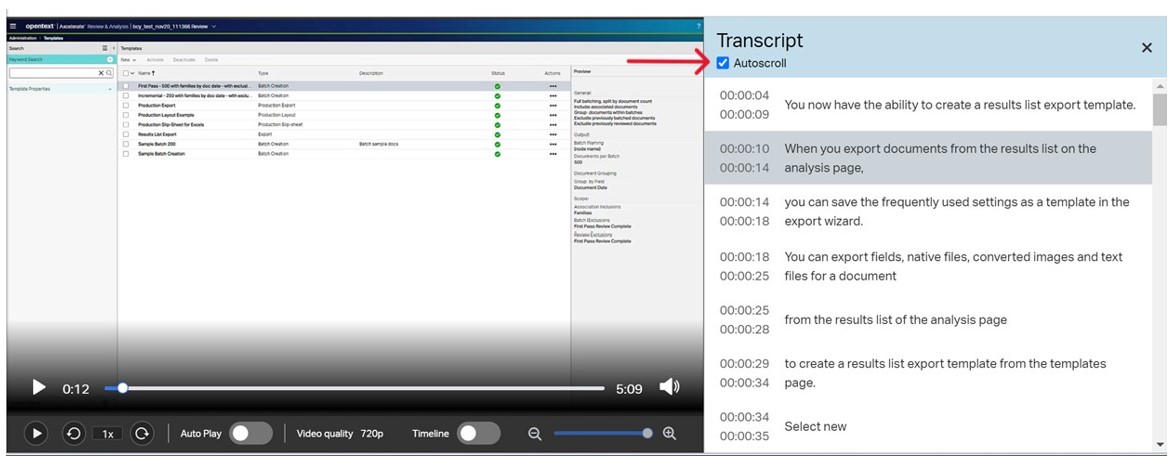
[Example 4: Audio-Video Player]
OpenText plans to continue expanding this new feature to include many more A/V support options, including:
- Ability to redact A/V files and/or their transcripts by timeline or time stamp selection
- Generation of redaction list menu for further navigation options
- Ability to assign redaction reasons to each markup
- Production of redacted A/V files natively
Other Structured Data and Use of Connectors
Another great way that OpenText eDiscovery supports other types of unstructured data is with the use of Data Connectors. These connectors allow data to be ingested directly into the platform from the original source system. This not only saves time, no longer having to deal with exported data, but it can be used for seamless transfer of other unstructured data from systems like Box, Atlassian Confluence, Google Drive, and more. Currently, OpenText eDiscovery has over 40 connectors.
In addition to OpenText eDiscovery’s chat features, newly released A/V support for Cloud, and Data Connectors, this platform has tons of other options for addressing unstructured data. For example, there are parsers for seamlessly ingesting forensic images without mounting the data. The Cloud Edition of OpenText eDiscovery has a special Native Excel viewer for seamless review of large Excel files. For more information, please take a look at the OpenText eDiscovery product overview.
[1] See Researchworld.com article “Possibilities and Limitations of Unstructured Data”.