

If you’re like most organizations, your capture workflows handle the bulk of your documents well. But there’s a category of content that takes more human effort: handwritten forms, overlapping tables, low-quality scans, and more. In fact, 37% of employees cite inadequate automation and repetitive tasks as a key obstacle to success1, a reminder that the complexity of real-world documents continues to outpace what most automated workflows can handle on their own.
To close that gap, we’re excited to announce OpenText™ Capture Aviator. A new AI document understanding add-on for OpenText™ Capture, Capture Aviator extends data extraction capabilities using visual and language understanding, powered by large language models (LLM), to read documents the way people do, recognizing context, interpreting layout, and effectively extracting data from content that doesn’t follow a predictable structure. You get higher straight-through processing rates on the documents that need it most, without changing how the rest of your workflows operate.
The documents that need a smarter approach
You’ve likely already automated the high-volume, semi-structured documents in your environment. The opportunity that remains is in the more complex content: documents that vary by source, degrade in transit, contain mixed formats, or are too infrequent to benefit from continuous machine learning or spending time creating templates.
These are documents that:
- contain inconsistent or unknown layouts
- include overlapping or highly variable tables
- feature handwritten inputs or annotations
- are scanned at low quality or degraded over time
- arrive too infrequently to justify the time to create templates or apply machine learning in production
Each one becomes a process exception, and every exception means more manual effort and slower cycle times across intelligent document processing solutions you’ve already invested in.
Expand automation, reduce complexity for intelligent document capture
AI document understanding extends your capture solution to gain additional actionable data from a broader range of document types. Capture Aviator applies LLM-based data extraction where you need it most, while preserving the continuous machine learning already running for your high-volume, semi-structured documents.
With Capture Aviator, you can:
- Route complex documents or those with low-confidence fields to LLM-based data extraction automatically
- Extract structured data from complex document elements, including overlapping tables, handwriting, and low-quality scanning—within a unified capture process
- Apply LLM data extraction to specific documents within capture workflows, enabling more flexible and context-aware processing
- Extend data extraction to new or variable document formats without adding additional processing steps or workflow changes
- Keep human validation and exception handling only where you need it
The result is a smarter intelligent document capture environment, with AI document understanding filling the gaps without disrupting the workflows that are already performing well.
What AI document understanding makes possible
Key capabilities of Capture Aviator include:
- Complex table extraction: Capture structured data from dense, overlapping, or layout-dependent tables without custom logic or template maintenance
- Handwriting recognition: Convert handwritten text and annotations into structured, usable data
- Low-quality document processing: Extract data from skewed, crumpled, or low-resolution scans
- Rapid onboarding of new document types: Configure extraction for new formats in minutes, even for low-volume or highly variable documents
- Context-aware validation: Identify inconsistencies that can be auto-flagged as exceptions within existing workflows
AI document understanding in action
Here are examples where LLM-based data extraction makes a measurable difference in intelligent document processing solutions:
- Crumpled or degraded receipts: Poor image quality and variable line-item layouts are handled effectively. Header data and line items are extracted regardless of image condition or format variation, so your approval and payment workflows keep moving.
- Handwritten patient intake forms: Mixed print and cursive, skipped fields, and non-standard layouts are processed with confidence scoring. Patient data is extracted into structured fields and routed for review only when needed, reducing manual work and speeding up downstream workflows.
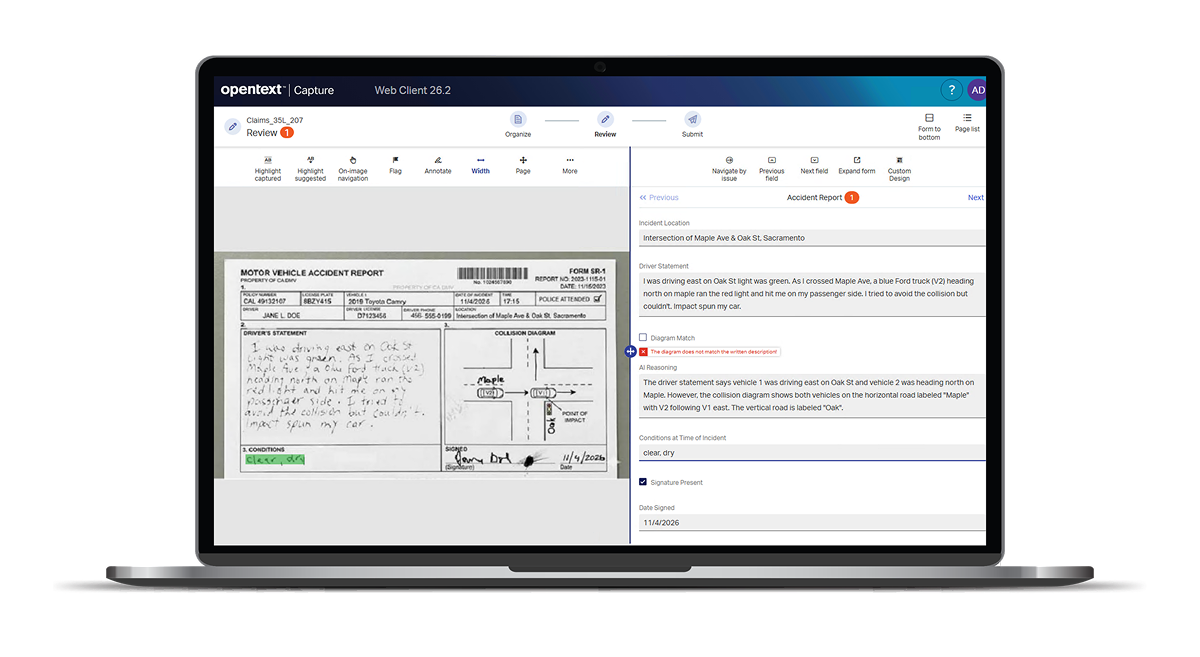
- Vehicle accident reports: Handwriting, diagram annotations, and inconsistent field placement are no longer barriers. Structured data is extracted and field inconsistencies can be auto-flagged before the record enters the claims workflow, reducing manual keying and improving data quality.
Embedded in OpenText Capture, not a separate tool
Capture Aviator is embedded directly within OpenText Capture, not a parallel platform that requires integration or retraining. You extend your existing workflows without redesign, and extracted data flows into downstream systems as trusted, workflow-ready information.
Your team keeps the governance, compliance, and exception handling processes already in place. AI document understanding steps in on the hard cases, and everything else continues unchanged. This is modernizing your intelligent document capture without starting over.
From data extraction to trusted business outcomes
By extending automation to complex and variable documents, your organization can:
- Increase straight-through processing by automating documents that previously required manual handling
- Reduce operational costs by targeting your use of LLM and minimizing manual exception handling and rework
- Accelerate time-to-value by integrating LLMs into capture solutions from the start
- Simplify setup and quickly expand data extraction with rapid onboarding of new document types, even low-volume or highly variable ones
- Meet organizational GenAI goals with a practical, production-ready approach to LLM-based data extraction
- Avoid third-party licensing complexity by accessing LLM capabilities directly through OpenText
Bring more documents into automation
With AI document understanding, OpenText Capture and Capture Aviator give you a practical way to expand automated data extraction across your full document landscape. By combining proven intelligent document capture capabilities with LLM-based data extraction, you get higher accuracy, greater efficiency, and the ability to increase straight-through processing rates.


