
What is Apache Spark?
Apache Spark is a distributed compute engine that provides a robust API for data science, machine learning, or to work with big data. It is fast, scalable, simple, and supports multiple languages, including Python, SQL, Scala, Java, and R. Backed by the Apache 2.0 license and supported by a huge open-source community, it is the go-to tool for big data computations.
Vertica and Spark
Spark fits naturally into a workflow with Vertica. For example, Vertica acts as a Data Warehouse and Spark is the “user” of the data. Common use cases for Spark include processing data from Vertica to enrich a model or transform data upstream before storing it in Vertica.
The Vertica Spark Connector
The Vertica Spark Connector is an open-source project developed to facilitate data transfer between Spark and Vertica in parallel to have an advantage with scaling as compared to JDBC/ODBC when transferring large amounts of data between Spark and Vertica. Since the connector uses the Spark DataSource V2 API, it is able to integrate directly into Spark SQL query planning and optimizations. The connector also supports additional options specific to Vertica, making it the preferred way to connect Spark to Vertica.
The Vertica Spark Connector is open-source and actively maintained by Vertica to support the latest Spark 3 releases. It is considered an upgrade from the older connector, which has been deprecated.
Some common usages of the connector are:
- Massive data ingestion into Vertica in parallel
- Integrate Vertica into existing Spark ETL pipelines
- Machine learning using VerticaPy and Apache Spark
How it Works
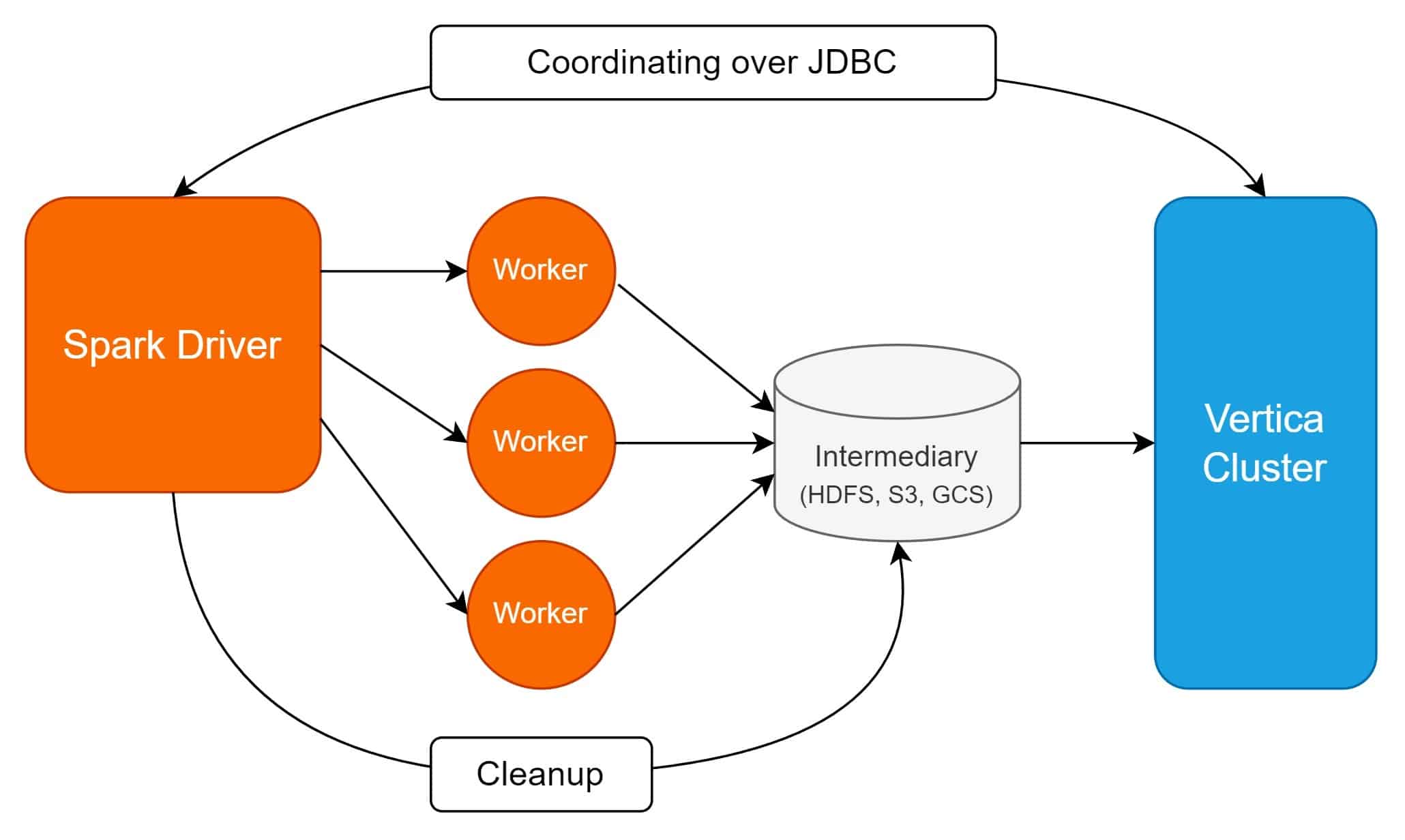
The connector does not use any proprietary protocol to handle parallel data transfer. Instead, it writes data onto an intermediary file store, like HDFS or S3, where Spark and Vertica both work on the data concurrently; Spark can assign multiple workers to process the data and Vertica can load or unload data concurrently.
For example, let’s assume that without the connector, you need to load a 100 million records DataFrame that was cleaned by a Spark workflow into Vertica. First, you would need Spark to write the data onto HDFS as Parquet, from which you will use Vertica’s COPY statement to bulk-load the data from HDFS. If you want Spark to process these again, you would do the reverse; use EXPORT_TO_PARQUET to unload data onto HDFS, then have Spark ingest the data.
The connector works on the same ideas and automates many of the necessary steps, like Vertica query generations, preparing data on the staging file store, cleaning up the file store after each operation, handling pushdowns from Spark SQL, and more. This is all achieved with the help of Spark’s DataSource V2 API. The connector uses JDBC to control and coordinate data transfer, but the data itself is transferred via an intermediary filestore such as HDFS, S3, or GCS.
Diagram of a write operation to Vertica:
Features
In addition to reading/writing data to Vertica in parallel, the connector also:
- Works with different file stores, including Amazon’s S3 and Google Cloud Storage
- Compatible with all Spark 3 releases
- Tested against latest Vertica releases down to Vertica 10, but may still work with older versions of Vertica
- Supports Kerberized HDFS and Vertica
- Can pushdown columns, filters, aggregates, and Vertica SQL queries
- Supports complex data types (Array, Row, etc)
- Scales horizontally by adding more Spark workers/Vertica nodes
And more! Visit our GitHub page more a detailed list of options and example videos.
Examples
To use the connector you will need:
- The connector JAR (available in Maven)
- A supported intermediary file store
- A Spark 3 cluster
You can find more information on how to set up the connector on our GitHub page.
Assuming your environment is ready to perform any operations, you simply have to specify the Vertica format name and the correct parameters. The options work exactly the same between the supported languages of Spark.
The following are small code samples that demonstrate some basic operations with the connector using PySpark.
Preparing Data
First, let’s initialize a Spark session and prepare some sample data:
from pyspark import sql
# Create the spark session
spark = SparkSession \
.builder \
.appName("Vertica Connector Pyspark Example") \
.getOrCreate()
# Prepare some sample data
columns = ["language","users_count"]
data = [("Java", 20000), ("Python", 100000), ("Scala", 3000)]
rdd = spark_context.parallelize(data)
# Convert the RDD to a DataFrame
df = rdd.toDF(columns)Required Connector Options
The following options are always required. They are used to connect to Vertica and the staging file store:
# Base options to connect to Vertica
host="Vertica-node-hostname"
user="jdbc-user"
password="jdbc-password"
db="vertica-db"
staging_fs_url="hdfs://hdfs:50070/data/"
table="lang_users_count"where
host is the hostname (or an IP address) of a Vertica node
user and password are your Vertica JDBC credentials
db is the name of your Vertica database
staging_fs_url is the path to the location on your intermediary file store that you want to use
Lastly, table is the name of the table that you want to read from/write to
Writing Data
In this example, we will clean the data above, only storing popular languages into Vertica.
# Doing some cleaning
cleaned_data = df.filter(df.users_count > 10000)
# Write the DataFrame to table "users_count" in Vertica with overwite mode
cleaned_data.write.mode('overwrite').save(
format="com.vertica.spark.datasource.VerticaSource",
# Connector specific options
host=host,
user=user,
password=password,
db=db,
staging_fs_url=staging_fs_url,
table=table
)Notice the write mode. With “overwrite”, the table users_count will be dropped in Vertica, if it exists, before recreating with our new data. The connector supports all Spark save modes.
In comparison, here’s how you would write a Parquet file to the location at staging_fs_url:
cleaned_data.write.mode('overwrite').parquet('hdfs://hdfs:50070/data/')Reading Data
This snippet will load the table users_count from Vertica onto a Spark DataFrame:
# Read the data back into a Spark DataFrame
readDf = spark.read.load(
format="com.vertica.spark.datasource.VerticaSource",
# Connector specific options
host=host,
user=user,
password=password,
db=db,
table=table,
staging_fs_url=staging_fs_url
)
readDf.show()Additional Capabilities
The Vertica Spark Connector has many options and capabilities. Our readme contains a detailed list of options as well as a good overview of compatibilities and capabilities. With that said, here are some of the things the connector can do.
Using Amazon S3
If you are working with an AWS stack like Amazon EMR, you can take advantage of using S3 as the staging file store. You will need to include a version of org.apache.hadoop.hadoop-aws based on your Spark installation. Then, specify your S3 bucket key and secret into the connector options with the staging path pointing to an S3 bucket location. For more information, check out the S3 manual on our GitHub page and our S3 example.
Working with External Data
The connector can also read and write data to an external table when the option create_external_table is specified.
Pushdown
Since the connector uses the DataSource V2 API, it can push down columns, filters, and supported aggregates to Vertica EXPORTS statement when reading from Vertica. This is done automatically by Spark and does not require any additional configurations.
Query Pushdown
However, there are cases where you may want to override the query generated by the connector to query data when reading from Vertica. For example, as of Spark 3.3.1 the DataSourceV2 API does not support join pushdown yet, but you can manually pushdown a join using the query option. A limitation of the query option is that the result of the query cannot contain any complex types.
Support for Vertica External Tables
In some cases, you may not want to load a large raw dataset to Vertica, especially if you would like to process data first or the same data is shared with several consumers. Support for external tables in the Vertica Spark Connector addresses exactly these use cases and enables linking existing data in HDFS or S3 compliant file stores directly to Vertica and performing reads from Spark. This allows performing querying and processing data utilizing Vertica capabilities and numerous optimizations to access remote data.
The Spark Connector includes two modes of operation. First is writing data to HDFS/S3 and automatically linking data by creating an external table.
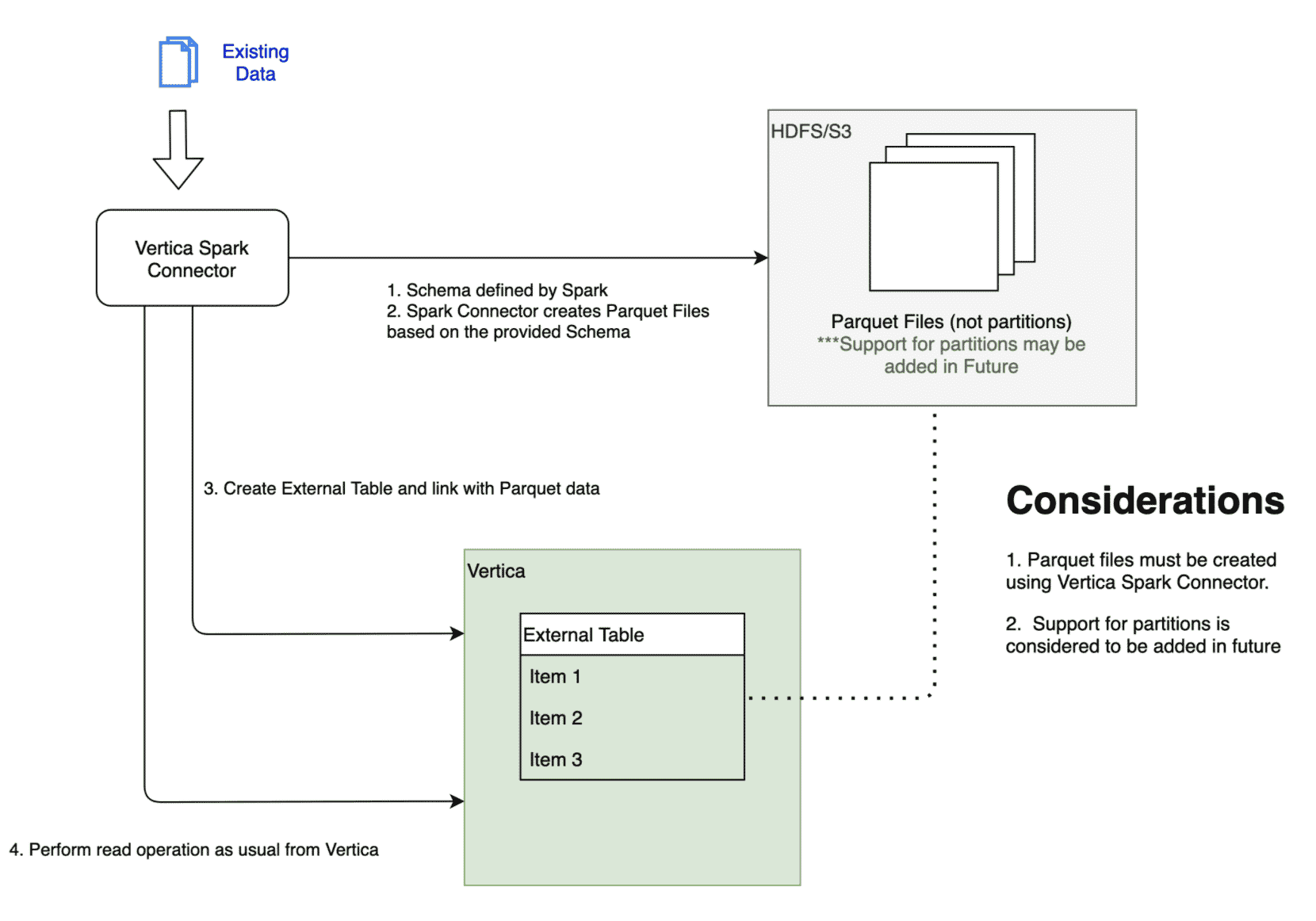
The second mode of operation works with existing data in HDFS or S3.
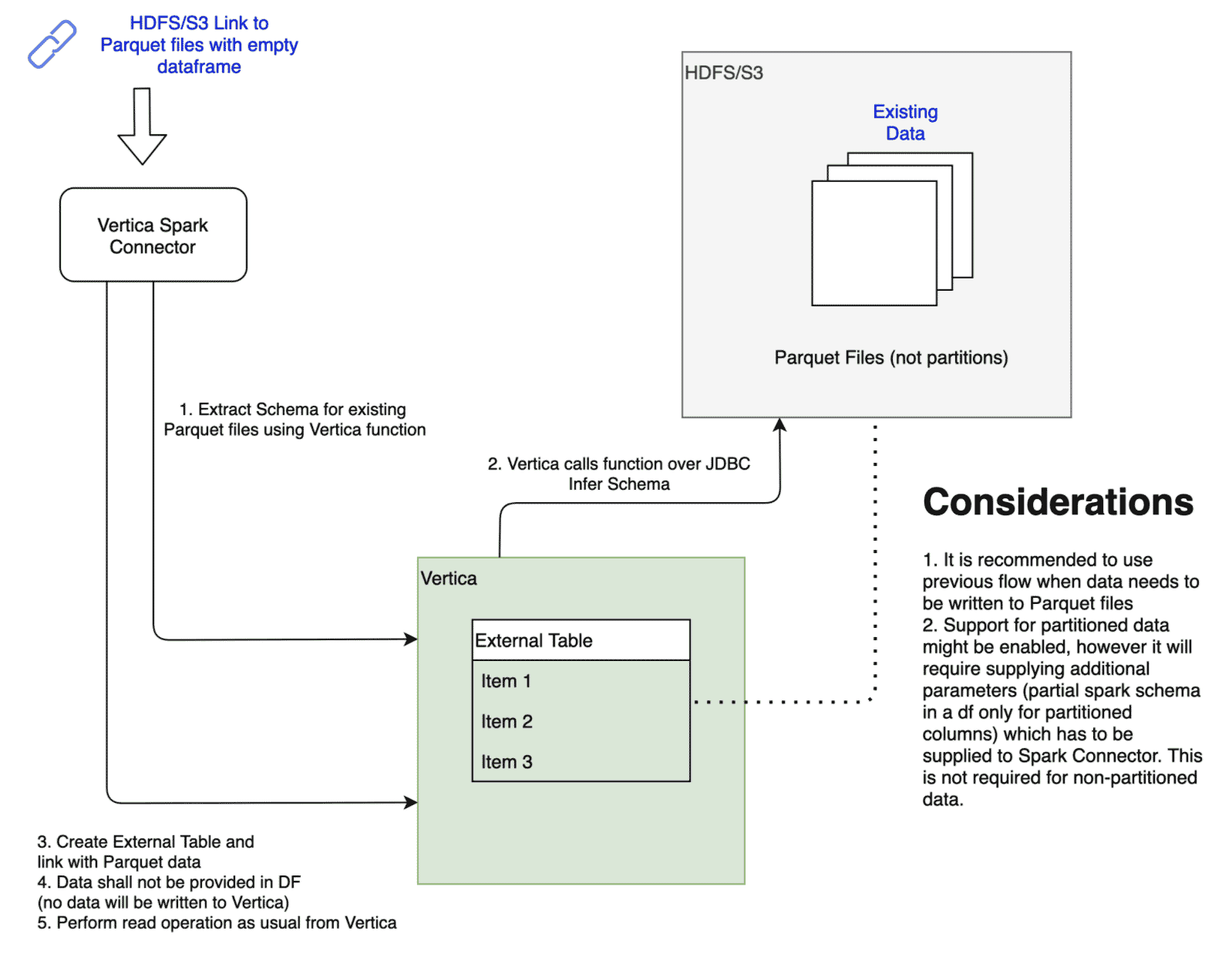
Support for Merge Statements
With the implementation of merge statements in our connector, users can process raw data in Spark and merge that data with an existing table in Vertica. The processed data will be written to a temporary table in Vertica before being merged. In the existing table, matched records will be updated and new records will be inserted, effectively constituting an “Upsert”. In order to execute a merge statement in our Spark Connector, the user needs to pass in a mergeKey, which will likely be an array of column attributes to join the existing table and temporary table on. If this option is not populated, a write will be performed as usual without the use of a temporary table.
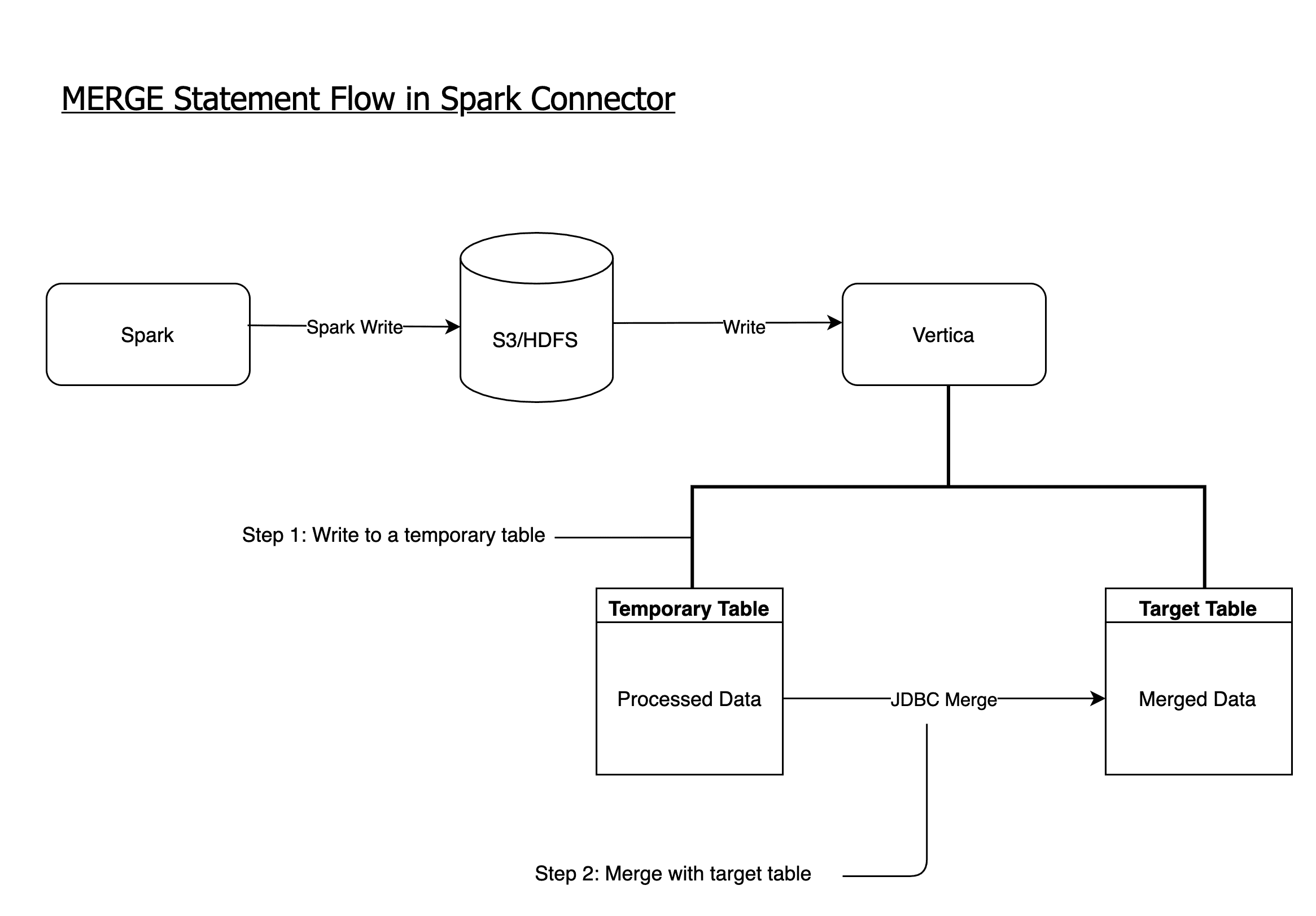
See an example merge use case here.
SSO and Kerberos
Setting up a Kerberized environment might be a lengthy and difficult process, especially when it is required to install multiple components, like Spark, HDFS, Vertica, and Linux KDC. The new Spark Connector not only supports Kerberos out of the box but also provides an easy to run reproducible Docker Compose script, which can spin up a new development environment in minutes.
For more information on how to create a local environment with Linux KDC, HDFS, Spark, and Vertica, visit our Docker setup on GitHub.
More Examples
For more examples, visit our GitHub page where you can find more comprehensive examples in Scala. Configuration is the same for all languages supported by Spark; specify the connector format name and provide the appropriate parameters. You can use our Scala example to see how to configure for different operations.


